• both the user and address documents will be maintained separately but the user document will contain a field that will reference the address document's id field.
(사용자 문서와 주소 문서는 별도로 유지되지만, 사용자 문서에는 주소 문서의 ID 필드를 참조하는 필드가 포함)
• the denormalized data model where related data is stored within a single document will be optimal (embedded reltaionship)(관련 데이터가 저장되는 공식화된 데이터 모델 : 단일 문서가 최적 / 임베디드 Relationship)
• in some cases, it makes sense to store related information in separate documents, typically in different collections or databases (normalized relationship)
(경우에 따라 관련 정보를 별도로 저장하는 것이 타당 / 일반적으로 서로 다른 컬렉션 또는 DB 에 있는 문서(정규화된 관계))
2) two methods for relating documents in mongoDB applications(몽고디비 응용프로그램에서 Document와 관련된 2가지)
• Manual references(수동 참조)
– you save the _id field of one document in another document as a reference. Then your application can run a second query to return the related data.
(하나의 document에 id 필드를 저장하고 다른 document에서 참조하면 된다 / 응용프로그램에서 두 번째 쿼리를 실행하여 반환할 수 있다)
– simple and sufficient method for most use cases.
(대부분의 사용 사례에 대한 간단하고 충분한 방법)
• DBRefs
– references from one document to another using the value of the first document‟s _id field, collection name, and, optionally, its database name
(dbrefs를 사용하여 한 문서에서 다른 문서로 참조 / _id 필드, 컬렉션 이름 및 데이터베이스 이름(선택 사항) 등이 있다)
– in cases where a document contains references from different collections, we can use this method
1) MongoDB provides atomic operations on only a single document
(몽고디비는 단일 document)에서만 atomic operations 을 제공
2) The recommended approach to maintain atomicity(원자성 유지하기 위한 권장하는 접근법)
• keep all the related information, which is frequently updated together in a single document using embedded documents(임베디드 문서를 사용하여 단일 문서로 자주 업데이트 되는 모든 관련 정보를 보관)
=> all the updates for a single document are atomic.(단일 document 에 대한 모든 업데이트는 원자적)
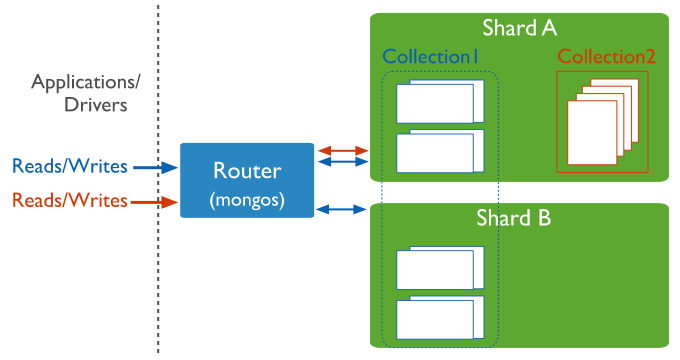
2. Sharding in mongoDB(목적 : 데이터 분산 저장(부하 분산) / 백업, 복구 전략(안정적) / 빠른 처리 성능)
- 시스템이 더 이상 부하를 견디지 못할 때, Sharding 을 통해 가용성을 늘려주고, 버틸 수 있는 throughput도 늘려준다
- a method for distributing data across multiple machines by horizontal scaling to meet the demands of data growth
- adds more machines (scale out ) to support data growth and the demands of read and write operations
- for storage and load distribution
- 왜 샤딩을 사용하나?
In replication, all writes go to master node
Latency sensitive queries still go to master
Single replica set has limitation of 12 nodes
Memory can't be large enough when active dataset is big
Local disk is not big enough
Vertical scaling is too expensive
shard: Each shard contains a subset of the sharded data. Each shard can be deployed as a replica set.
각 샤드에는 샤드 데이터의 하위 집합이 포함 / 각 샤드는 replica set로 배치한다.(고가용성 위해)
sharded cluster 안에서 sharded data의 subset을 가진다
clusert의 shard 들에 존재하는 데이터를 합하면 원본의 데이터가 된다.
하나의 shard에 대해 query를 실행하면 , 해당 shard 안의 데이터에 대해서만 결과를 가져온다 / cluster level에서 query를 실행하고 싶다면, mongos 사용
하나의 데이터베이스 안에 primary shard(shard 되지 않은 모든 collection 저장) 는 반드시 존재
mongos(=routers): cache the cluster metadata and act as a query router, providing an interface between client applications and the sharded cluster.
클러스터 메타데이터를 캐시화하고, 클라이언트 어플리케이션과 Sharded 클러스터간의 인터페이스를 쿼리라우터 역할로서 제공한다.
적절한 shard 로 route 하기 위해 config server로부터 metadata를 캐싱
각각의 shrad에 대해 query 를 분산시키기 위해 mongos라는 instance를 제공
어떠한 data나 설정 정보를 저장하지 않는다.
mongos 서버를 통해 데이터를 읽고, 쓰고 / config 서버의 metadata를 캐시 / 빅데이터를 샤드 서버로 분산하는 프로세스
config servers: store metadata persistently and configuration settings for the cluster
클러스터에 대한 메타데이터 및 구성 설정을 영구 저장
모든 shard에 대해 어떤 chunk를 들고 있는지 정보를 가지고 있고, 해당 metadata를 mongos에서 활용하여 query를 route한다.
클러스터 설정 저장하는 server
config server로부터 data를 동기화 한다
샤드 서버의 인덱스 찾는데 필요/ 샤드 시스템에 대한 메타 데이터 저장 , 관리 역할
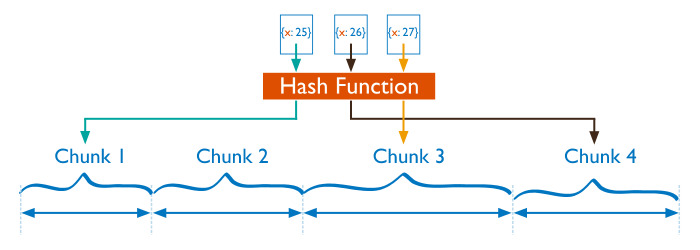
샤드 키 (shard keys)
used to distribute the collection‟s documents across shards
클러스터들의 샤드들 간에 collection의 document를 어떻게 분산할 것인가 결정
consists of a field or fields that exist in every document in the target collection
대상 집합의 모든 document에 존재하는 필드로 구성
컬렉션을 샤딩할 때, 샤드 키 선택 / 샤딩 후에는 변경 불가
여러 개의 shard 서버로 분할된 기준 필드 가르킴
partition 과 load balancing 의 기준, mongodb 데이터 저장과 성능에 절대적인 영향
청크(chunks)
a contiguous range of shard key values within a particular shard
특졍 샤드 내의 연속적인 샤드 키 값 범위
each chunk has an inclusive lower and exclusive upper range based on the shard key.
각 청크에는 샤드 키를 기반으로 하는 포괄적인 하한 범위와 배타적인 상위 범위가 존재한다.
default size : 64 MB
일정한 데이터양에 도달했을 때, 서버로 분할하는 단위
balancer and even chunk distribution
to achieve an even distribution of chunks across all shards in the cluster, a balancer runs in the background to migrate chunks across the shards when a shard contains too many chunks of a collection relative to other shards
클러스터의 모든 파편에 걸쳐 고르게 분포하기 위해 , 샤드에 다른 파편에 비해 너무 많은 컬렉션 덩어리가 포함되어 있을 때, 밸런서가 백그라운드에서 실행되어 파편에 걸쳐 청크를 마이그레이션(데이터의 이동, 서버에 균등하게 데이터를 재조정하는 과정) 한다.
3. Sharding 의 이점
• 읽기 및 쓰기 (Reads / Writes)
– read and write workloads can be scaled horizontally across the shards in the cluster by adding more shards.
– for queries that include the shard key or the prefix of a compound shard key, mongos can target the query at a specific shard or set of shards
– 샤드 클러스터의 샤드에 읽기 및 쓰기 워크로드를 분산시켜 각 샤드가 클러스터 작업의 서브 세트를 처리할 수 있도록
– 더 많은 샤드를 추가하여 읽기 쓰기 워크로드를 클러스터 전체에 수평적으로 확장 할 수 있게.
• 저장 용량 (Storage Capacity)
– each shard contains a subset of the total cluster data
– as the data set grows, additional shards increase the storage capacity of the cluster.
– 클러스터의 샤드에 데이터를 분산시켜 각 샤드가 전체 클러스터 데이터의 서브 세트를 포함.
– 데이터 세트가 커짐에 따라 , 추가 샤드가 클러스터의 스토리지 용량을 증가
• 고가용성 (High Availability)
– a sharded cluster can continue to perform partial read / write operations even if one or more shards are unavailable
– in production
– 클러스터는 한 개 이상의 shard를 사용할 수 없는 경우에도 부분 읽기 / 쓰기 작업을 계속 수행할 수 있음.
» 각 shard는 복제 세트로 구성 » config server는 최소 3개의 노드들로 구성된 복제 세트로 구성
4. Sharded and Non-Sharded Collections(샤드 및 비샤드 컬렉션)
• A database can have a mixture of sharded and unsharded collections
- 데이터베이스에 샤드와 비샤드 컬렉션이 혼합되어 있을 수 있음
• Sharded collections are partitioned and distributed across the shards in the cluster. Unsharded collections are stored on a primary shard
apply operations asynchronously using oplog from the primary so that they have the same data set
oplog에 기록된 내용들을 동일하게 연산하여 주 노드와 항상 같은 데이터 유지
a node without data(optional)
an arbiter node(PRIMARY / SECONDARY 서버를 모니터링 해주는 역할(끊어지는지 확인 가능)):결정권자
결정권 자는 주 노드의 데이터를 복제하지 않는다
데이터가 없기 때문에, 주 노드가 될 수 없다
역할 : heartbeat를 통해 노드의 상태를 확인하고 , 유사 시 선거에만 참가
arbiter(결정권자)
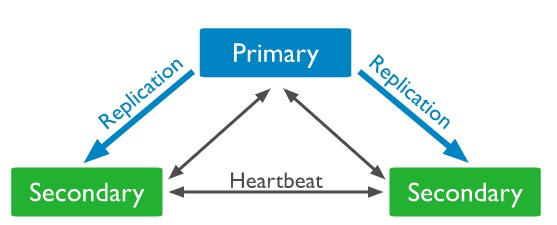
기본적인 Replica Set 구성
2. 주 노드의 교체
=> 주 노드와 보조 노드 사이에 주기적으로 주고 받는 heartbeat(=ping/ 2s) 신호 통해 주 노드가 정상적이지 않은 상황 발견하면, 나머지 보조 노드들의 선거(election)을 통해 새로운 주 노드를 선발 => 원래 주 노드가 정상 상태로 돌아오면, 다시금 주 노드의 역할 맡게 된다
=> replicate the primary’s oplog and apply the operations to their data sets such that the secondaries’ data sets reflect the primary’s data set
=> Replica set members send heartbeats (pings) to each other every 2 seconds. If a heartbeat does not return within 10 seconds, the other members mark the member as inaccessible.
주 노드 서버가 정상인 경우
주 노드 서버 정상
주 노드 서버가 정상 작동하지 않는 경우(primary node 대체 : automatic failover)
주 노드 서버가 정상 작동하지 않음
- 보조 노드들은 자신들의 상태, 미리 지정한 Priority 값을 판단하여 어떤 보조 노드가 주 노드로 승격될 것인지 선거
- 만약, 점수가 동일하게 나오면 가장 최근에 반영된 데이터를 반영한 보조 노드가 승격 대상
- 선거가 끝나기 전 까지 Read 수행은 보조 노드를 통해 가능하게 미리 설정(선거 시간 10초 넘기지 않는다)가능, Write는 주 노드가 없는 상태이므로 불가능
- 주 노드가 정상 상황 아닌 경우 실패한 write 연산을 retry 하는 기능 있음
- If the primary is unavailable, an eligible secondary will hold an election to elect itself the new primary node (기본 선거 시간 : 10초)
- The replica set cannot process write operations until the election completes successfully
- The replica set can continue to serve read queries if such queries are configured to run on secondaries while the primary is offline
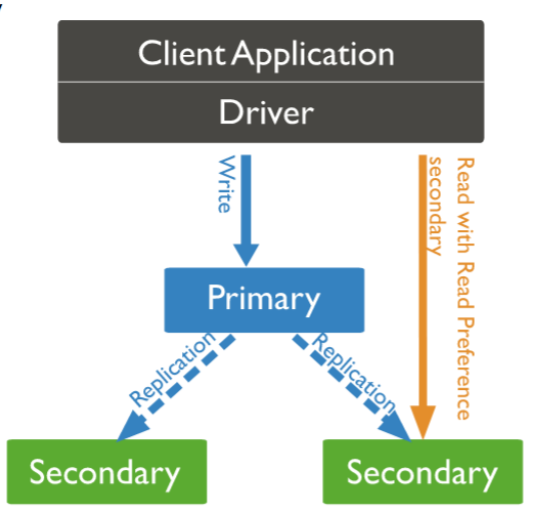
3. Read 연산(read preference)
read preference
- 기본적, 응용 프로그램은 읽기 작업을 복제세트의 기본 구성원으로 보냄
그러나, 클라이언트는 읽기 기본 설정을 지정하여 읽기 작업을 보조로 보낼 수 있다.
- secondary 에 대한 비동기식 복제는 secondary가 primary data 상태를 반영하지 않은 data를 반환한다
- By default, clients read from the primary; however, clients can specify a read preference to send read operations to secondaries.
- Asynchronous replication to secondaries means that reads from secondaries may return data that does not reflect the state of the data on the primary.
4. 여러 데이터 센터에 Replica Set 분산
복수의 데이터 센터에 멤버들을 어떻게 분산?
각 DB 노드들을 데이터 센터 분산에서는 멤버(member)로 호칭
데이터 센터의 수를 홀수로 하면, 선거에서 동점이 나올 확률 줄일 수 있다.
각 데이터 센터에는 최소한 1개의 멤버를 배포하는 것이 원칙
주로 서비스를 수행할 데이터 센터와, 대체 운영 및 백업의 목적인 데이터 센터를 결정
주 노드를 뽑는 선거는 모든 멤버 50% 이상의 과반수 득표를 해야 함
과반수의 멤버를 특정 데이터 센터에 분산
- EX ) Replica Set 멤버가 5인 경우
Case 1) 2개의 데이터 센터
3개의 멤버는 데이터 센터 1에, 2개의 나머지 2개의 멤버는 데이터 센터 2에 분산한다.
- 만약 데이터 센터 1에 문제가 발생하면, replica set은 READ ONLY가 된다.
- 만약 데이터 센터 2에 문제가 발생하면, 데이터 센터 1의 멤버들의 수는 여전히 과반수가 넘으므로,
replica set은 WRITE가 가능하다.
Case 2) 3개의 데이터 센터
2개의 멤버는 데이터 센터 1에, 2개의 나머지 2개의 멤버는 데이터 센터 2에, 1개의 멤버는 데이터 센터 3에 배포.
- 만약 어떤 데이터 센터에 문제가 발생하더라도, 나머지 데이터 센터의 멤버들이 선거가 가능한 상황이므로, replica set은 WRITE가 가능하다.
어느 데이터 센터가 문제가 생기더라도 주 노드의 유지가 가능한 멤버 분포각 복제 멤버의 우선 순위 설정값을 통해, 주 노드로의 승격 가능성 조정
데이터 센터 수가 많을 수록 멤버들은 고루 분포되기 때문에, 선거 때 동점이 발생할 수 있고, 관리자가 사전에 특정 데이터 센터 내의 멤버들이 선거에서 주 노드로 선택될 확률을 더 많이 주고 싶을 수 있다.
=> 각 멤버 속성을 정의할 때, Priority 값을 미리 정의하여 조정할 수 있다.
- EX) Replica Set 멤버가 3인 경우
Case 1) 2개의 데이터 센터
두 개의 멤버는 데이터 센터 1에, 나머지 하나의 멤버는 데이터 센터 2에 둔다. 만약 결정권자(arbiter)를 둔다면, 멤버의 수가 더 많은 데이터 센터 1에 운영한다.
- 데이터 센터 1에 문제가 발생하면, 과반수의 멤버가 불능이 되어, 선거를 할 수 없는 상황이다. 데이터 센터 1이 정상적인 상태로 돌아올 때까지 replica set 자체는 READ ONLY 상태가 된다.
- 데이터 센터 2에 문제가 발생하면, 데이터 센터 1의 멤버들은 과반수이고 선거를 할 수 있으므로, 새로운 주 노드를 선임하여, replica set은 여전히 WRITE가 가능하다.
위와 같이, 데이터 센터 2개의 경우, WRITE가 불가능한 상황이 발생할 수 있기 때문에, 데이터 센터의 수는 최소 3개 이상으로 하는 것이 안전하다.
Case 2) 3개의 데이터 센터
각각의 데이터 센터에는 멤버가 1개씩 존재하는 구조가 된다.
- 데이터 센터 1,2, 3 어디든 문제가 발생하면, 나머지 2개의 멤버들은 선거를 통해 새로운 주 노드를 찾을 것이고, replica set은 여전히 WRITE가 가능하다.
// import된 각 패키지들에 대한 설명은 API 문서 참조
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient myclient = new MongoClient("localhost" , 27017);
// 또는 MongoClient myclient = new MongoClient();
System.out.println("Connected to the database successfully");
// Accessing the database (db가 없으면 새로 생성)
MongoDatabase mydb = myclient.getDatabase("sdb");
}
}
- 컬렉션 생성
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient myclient = new MongoClient();
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase mydb = myclient.getDatabase("sdb");
//Creating a collection
mydb.createCollection("sampleCol");
System.out.println("Collection created successfully");
}
}
- 특정 DB 내의 모든 컬렉션 이름 출력
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
. . .
public class ListOfCollection {
public static void main( String args[] ) {
. . .
// Accessing the database
MongoDatabase mydb = myclient.getDatabase("sdb");
// listing all collections
for (String name : mydb.listCollectionNames()) {
System.out.println(name);
}
}
}
- 컬렉션 선택(반환)
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import org.bson.Document;
public class selectingCollection {
public static void main( String args[] ) {
. . .
// Accessing the database
MongoDatabase mydb = myclient.getDatabase("sdb");
// Retrieving a collection
MongoCollection<Document> mycol = mydb.getCollection("sampleCol");
System.out.println("Collection Col selected successfully");
}
}
-컬렉션 제거(drop)
import com.mongodb.client.MongoCollection;
. . .
public class DroppingCollection {
public static void main( String args[] ) {
. . .
// Accessing the database
MongoDatabase mydb = myclient.getDatabase("sdb");
// Retrieving a collection
MongoCollection<Document> mycol = mydb.getCollection("sampleCol");
// Dropping a Collection
mycol.drop();
System.out.println("Collection dropped successfully");
}
}
- document삽입
. . .
import org.bson.Document;
public class insertingDocument {
public static void main( String args[] ) {
. . .
// Retieving a collection
MongoCollection<Document> mycol = mydb.getCollection("sampleCol");
System.out.println("Collection Col selected successfully");
// bson Document 객체 생성
Document mydoc = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "http://www.tutorialspoint.com/mongodb/")
.append("by", "tutorials point");
mycol.insertOne(mydoc);
System.out.println("Document inserted successfully");
}
}
-컬렉션 내 모든 문서 검색
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import java.util.Iterator;
. . .
public class RetrievingAllDocuments {
public static void main( String args[] ) {
. . .
// Retrieving a collection
MongoCollection<Document> mycol = mydb.getCollection("sampleCol");
// Getting the iterable object
FindIterable<Document> iterDoc = mycol.find();
// Getting the iterator
Iterator it = iterDoc.iterator(); // iterator 반환
int i = 1;
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}
-document 수정
import com.mongodb.client.MongoCollection;
import com.mongodb.client.FindIterable;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
. . .
public class UpdatingDocuments {
public static void main( String args[] ) {
. . .
// Updating a document
mycol.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Getting the iterable object
FindIterable<Document> iterDoc = mycol.find();
// Getting the iterator
Iterator it = iterDoc.iterator(); // iterator 반환
int i = 1;
while (it.hasNext()) {
System.out.println(it.next()); i++;
}
}
}
- document 삭제
import com.mongodb.client.MongoCollection;
import com.mongodb.client.FindIterable;
import com.mongodb.client.model.Filters;
. . .
public class DeletingDocuments {
public static void main( String args[] ) {
. . .
// Deleting a document
mycol.deleteOne(Filters.eq("id", 1)); // deleteMany() 메소드
System.out.println("Document deleted successfully...");
// Getting the iterable object
FindIterable<Document> iterDoc = mycol.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator(); // iterator 반환
while (it.hasNext()) {
System.out.println(it.next()); i++;
}
}
}
-조건에 맞는 특성 문서 검색
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import java.util.Iterator;
. . .
public class RetrievingAllDocuments {
public static void main( String args[] ) {
. . .
// Retrieving a collection
MongoCollection<Document> mycol = mydb.getCollection("sampleCol");
// Finding a document with find(Bson filter) method
// and Getting the iterable object
FindIterable<Document> iterDoc = mycol.find(검색조건); // 커서 반환
//검색 조건 : find() / delete() / update() 조건 표현은 동일
//각종 메소드 활용 가능
. . .
}
}
SQL과의 비교(SQL count(*) 에서 group by 는 mongodb 집계와 동일)
select
$project, $group 함수($sum, $min, $avg 등)
from
aggregate()
join
$unwind
where
$match
group by
$group
having
$match
aggregation 표현식 목록
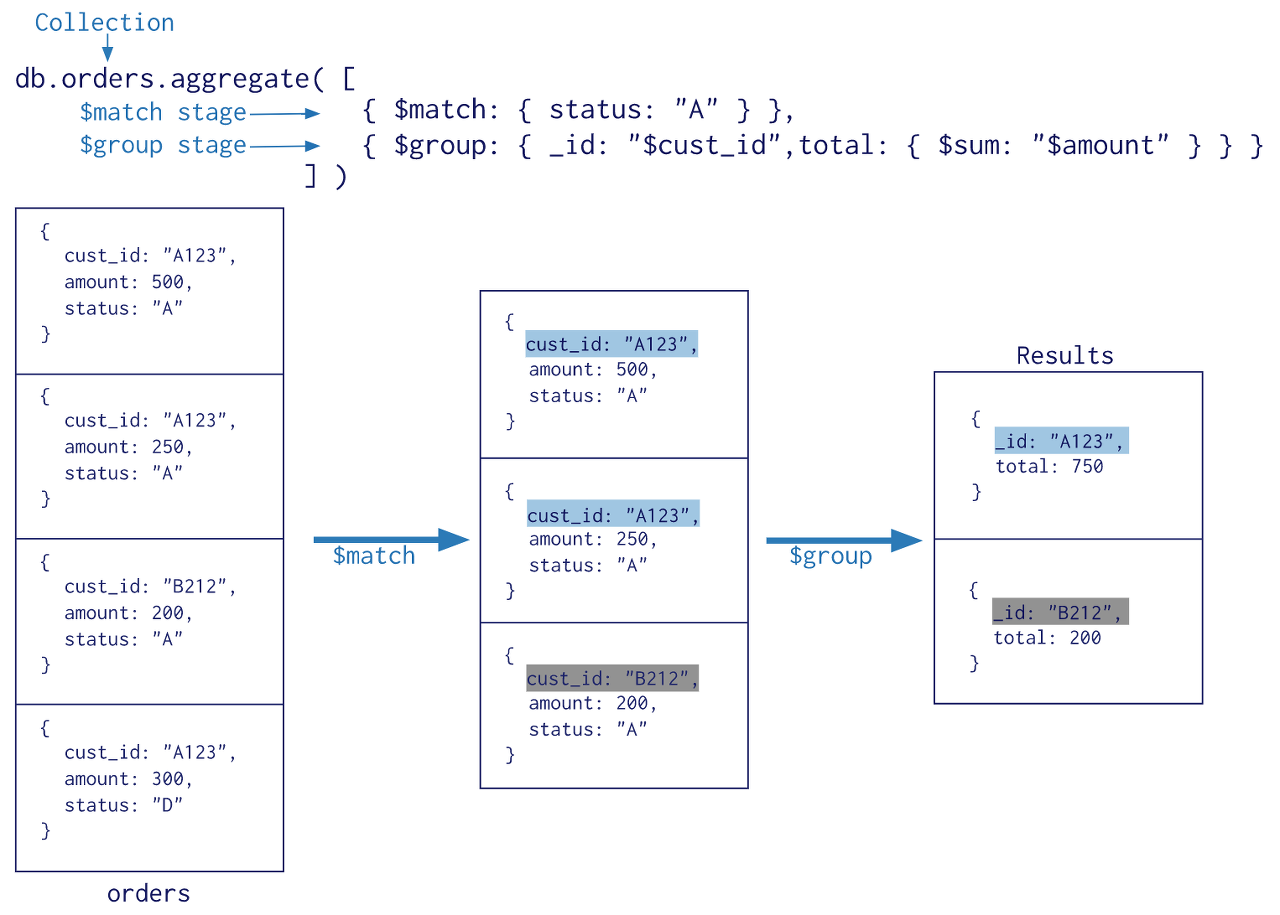
> db.mycol.aggregate([ {$group : { _id : "$by_user“ , num_tutorial : {$sum : 1} }} ]) //출력될 문서의 형식 { _id : 값1, num_tutorial : 값2 } //$가 붙은 문자열 필드 값은 일반 문자열 값이 아닌 입력 문서의 특정 필드를 지정
> db.mycol.aggregate([{$group :{_id :"$by_user", num_tutorial :{$sum :1}}}]) { "result":[ { "_id":"tutorials point", "num_tutorial":2 }, {"_id":"Neo4j", "num_tutorial":1 } ],"ok":1 }//각 사용자가 작성한 자습서 수 나타내는 목록
$sum -> 각 그룹에 대해 그 그룹에 속하는 문서가 있을 때 마다 num_tutorial 필드 값을 1씩 증가
$avg -> 컬렉션의 모든 문서에서 제공된 모든 값의 평균 계산
$min -> 컬렉션의 모든 문서에서 해당 값의 최소값 가져옴
$max -> 컬렉션의 모든 문서에서 해당 값의 최대값 가져옴
$push -> 결과 문서의 배열에 값 삽입
$addToSet -> 결과 문서의 배열에 값을 삽입하지만 중복은 생성하지 않는다
$first -> 그룹화에 따라 소스 문서에서 첫 번째 문서를 가져옴 / 이전에 적용된 일부 "$sort" 단계와 만 의미 O
$last -> 그룹화에 따라 소스 문서에서 마지막 문서를 가져옴 / 이전에 적용된 일부 "$sort" 단계와 만 의미 O
// 배열 points의 요소들 중에 (15보다 큰 조건만을 만족하는 요소도 있으면서 20보다 작은 조건을 만족하는 또 다른 요소도 있는 문서) 또는 (한 요소가 15보다 크면서 20보다 작은 조건을 모두 만족)하는 문서 검색 > db.myCol.find( {“points”:{$gt:15, $lt:20} })
// 배열 points의 요소들 중에 적어도 하나라도 (21보다 크고 26보다 작은 조건을 모두 만족)하는 요소를 가지는 문서 검색 > db.myCol.find( {“points”:{$elemMatch:{$gt:21, $lt:26}} })
Q1) 이름이 joo이고 나이가 24인 친구를 가지고 있는 사람의 이름은? Q2) 나이가 22살 이하인 친구를 가지고 있는 사람의 이름은? Q3) 첫 번째 친구의 나이가 20인 친구를 가지고 있는 사람의 이름은?
2. Indexing(인덱스)
몽고 디비 쿼리에서 효율적인 실행을 지원 -> 인덱싱이 없이 몽고디비는 콜렉션 스캔을 실행하여야 한다. -> ex) 쿼리문에 일치하는 도큐먼트 선별하기 위해 컬렉션 내의 모든 도큐먼트를 스캔해야한다
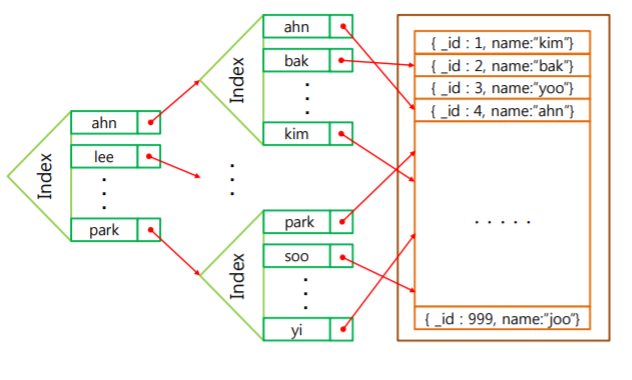
인덱스 : 콜렉션의 데이터셋의 작은 일부를 저장하고 있는 특별한 데이터 구조 -> 인덱스는 특정 필드 또는 필드 세트의 값을 인덱스에 지정된 필드 값 순서로 저장 -> 컬렉션내의 임의의 문서를 빠르게 접근하도록 하는 자료구조 ->인덱스는 데이터 파일과는 별도의 파일에 저장됨 ->검색 속도를 향상시키나 인덱스 저장 공갂 필요 -> 삽입, 삭제, 수정 연산의 속도 저하
인덱스의 구조 -> 엔트리 구조 : < 탐색 키 필드, 문서에 대핚 포인터 > ->엔트리들은 탐색 키 필드 값의 오름차순으로 정렬되어 있음
다단계 인덱스 : B, B+ 트리 사용
1) ensureIndex() 메서드
db.COLLECTION_NAME.ensureIndex({KEY : 1})
-> key 는 색인을 작성하려는 필드의 이름 / 1은 오름차순 / 내림차순으로 인덱스를 만들려면 -1
-> 여러 필드에 인덱스를 만들려면 여러 필드를 전달할 수 있다.
>db.mycol.ensureIndex({"title" : 1}) >db.mycol.ensureIndex({"title":1,"description":-1}) //여러 필드 전달
ensureIndex() 메소드는 옵션 목록도 허용합니다.
PARAMETER
TYPE
DESCRIPTION
background
boolean
인덱스를 빌드해도 다른 DB 활동을 차단하지 않도록 백그라운드에서 인덱스를 빌드한다. 백그라운드에서 빌드하려면 TRUE / 기본값은 FALSE
unique
boolean
인덱스 키가 인덱스의 기존 값과 일치하는 문서 삽입을 허용하지 않도록 고유 인덱스를 생성/ 고유 인덱스를 작성하려면 TRUE 지정 / 기본값은 FALSE
name
string
인덱스의 이름/ 지정되지 않은 경우 mongodb는 인덱스화 된 필드의 이름과 정렬 순서를 연결하여 인덱스 이름을 생성
dropDups
boolean
중복될 수 있는 필드에 고유 인덱스를 작성 / mongodb는 키의 첫번째 항목만 인덱스화하고 해당 키의 후속 항목이 포함된 콜렉션에서 모든 문서를 제거 / 고유 인덱스를 작성하려면 true를 지정/ 기본값은 false
sparse
boolean
true인 경우 인덱스는 지정된 필드가 있는 문서만 참조 / 이 인덱스는 공간을 덜 사용하지만 일부 상황(정렬..) 에서 다르게 동작 / 기본값 false
expireAfterSeconds
Integer
mongodb가 콜렉션에서 문서를 보유하는 기간을 제어하기 위해 TTL 값을 초 단위로 지정
v
Index Version
색인 버전 번호 / 기본 인덱스 버전은 인덱스 작성시 실행중인 mongodb 버전에 따라 다름
weights
Document
가중치는 1~99,999 범위의 숫자, 점수를 기준으로 다른 색인화 된 필드에 대한 필드의 중요성 나타냄
default_language
string
텍스트 인덱스의 경우 중지 단어 목록과 형태소 분석기 및 토크 나이저에 대한 규칙을 결정하는 언어 / 기본값 english
language_override
string
텍스트 인덱스의 경우 기본 언어를 대체 할 언어를 포함하는 문서의 필드 이름 지정 / 기본값은 언어
2. 커서(5주차 추가 메뉴얼)
커서의 활용
find() 메소드 : 검색된 문서 집합에 대한 커서 반환
var 타입의 번수 사용하지 않는 경우
// mongo 쉘에서는 반환 결과를 변수에 할당하지 않으면 // 커서가 자동으로 20번 반복되어 문서 20개를 자동 출력 후 대기 // “it” 입력하면 커서 반복 > db.myCol.find()
var 타입의 변수 사용하는 경우
반환된 문서 집합에 대해 커서를 수동으로 반복하여 개별적 문서 접근
> var myCursor = db.myCol.find() > myCursor // 커서 20번 반복 -> 20개 문서 출력 후 대기
> var myCursor = db.myCol.find() > while (myCursor.hasNext()) { print(tojson(myCursor.next())); // printjson(myCursor.next()); }
커서 활용
검색 결과의 문서 개수 출력
> db.myCol.find.count() > var res = db.myCol.find.count() > res
3. Index 메소드
인덱스 생성 메소드 //createIndex()
db.컬렉션명.createIndex(<키> , <옵션>) // <키>는 문서 형식 {키:1 or -1, ... }으로 명세 (1:오름, -1:내림) // <옵션>도 문서 형식 {키:값, ... }으로 명세
단일 / 복합 인덱스 (single / compound index) 생성
db.mycol.createIndex({"age" : 1}) //단일 키 인덱스(하나의 필드만 사용)
db.mycol.createIndex({"deptname" : 1, "year" : -1}) //복합 키 인덱스 (2개 이상의 필드 사용) //키의 순서 중요