1. 데이터베이스 파티셔닝 (Database partitioning)
- 데이터베이스를 분리하여 여러 서버에 분산, 저장 및 관리하는 기술
- 파티셔닝 유형 (2가지)
- 수직 파티셔닝 (vertical)
- 하나의 테이블의 컬럼들을 여러 테이블로 분리하는 방법
- ex) R(A1, A2, A3, A4, A5) == > R1(A1, A2, A3, A4) / R2(A1, A5)
- 수평 파티셔닝(=샤딩)(horizontal)
- 로우 (문서) 별로 데이터베이스를 분할하는 방법
- 샤드(shard) : 분할된 각 데이터 조각 의미. 둘 이상의 서버에 분산 저장
- 수직 파티셔닝 (vertical)
2. Sharding in mongoDB(목적 : 데이터 분산 저장(부하 분산) / 백업, 복구 전략(안정적) / 빠른 처리 성능)
- 시스템이 더 이상 부하를 견디지 못할 때, Sharding 을 통해 가용성을 늘려주고, 버틸 수 있는 throughput도 늘려준다
- a method for distributing data across multiple machines by horizontal scaling to meet the demands of data growth
- adds more machines (scale out ) to support data growth and the demands of read and write operations
- for storage and load distribution
- 왜 샤딩을 사용하나?
- In replication, all writes go to master node
- Latency sensitive queries still go to master
- Single replica set has limitation of 12 nodes
- Memory can't be large enough when active dataset is big
- Local disk is not big enough
- Vertical scaling is too expensive
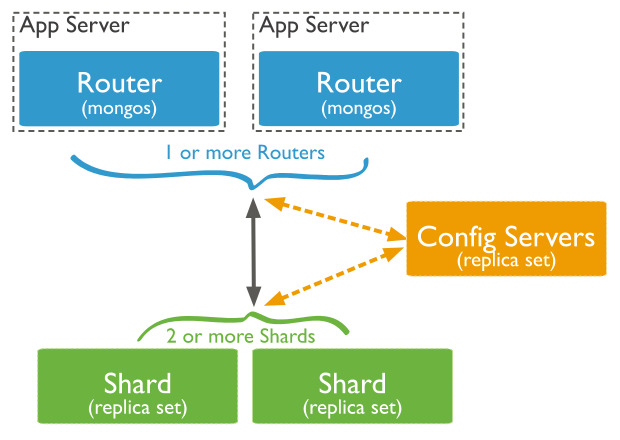
- shard: Each shard contains a subset of the sharded data. Each shard can be deployed as a replica set.
- 각 샤드에는 샤드 데이터의 하위 집합이 포함 / 각 샤드는 replica set로 배치한다.(고가용성 위해)
- sharded cluster 안에서 sharded data의 subset을 가진다
- clusert의 shard 들에 존재하는 데이터를 합하면 원본의 데이터가 된다.
- 하나의 shard에 대해 query를 실행하면 , 해당 shard 안의 데이터에 대해서만 결과를 가져온다 / cluster level에서 query를 실행하고 싶다면, mongos 사용
- 하나의 데이터베이스 안에 primary shard(shard 되지 않은 모든 collection 저장) 는 반드시 존재
- mongos(=routers): cache the cluster metadata and act as a query router, providing an interface between client applications and the sharded cluster.
- 클러스터 메타데이터를 캐시화하고, 클라이언트 어플리케이션과 Sharded 클러스터간의 인터페이스를 쿼리라우터 역할로서 제공한다.
- 적절한 shard 로 route 하기 위해 config server로부터 metadata를 캐싱
- 각각의 shrad에 대해 query 를 분산시키기 위해 mongos라는 instance를 제공
- 어떠한 data나 설정 정보를 저장하지 않는다.
- mongos 서버를 통해 데이터를 읽고, 쓰고 / config 서버의 metadata를 캐시 / 빅데이터를 샤드 서버로 분산하는 프로세스
- config servers: store metadata persistently and configuration settings for the cluster
- 클러스터에 대한 메타데이터 및 구성 설정을 영구 저장
- 모든 shard에 대해 어떤 chunk를 들고 있는지 정보를 가지고 있고, 해당 metadata를 mongos에서 활용하여 query를 route한다.
- 클러스터 설정 저장하는 server
- config server로부터 data를 동기화 한다
- 샤드 서버의 인덱스 찾는데 필요/ 샤드 시스템에 대한 메타 데이터 저장 , 관리 역할
- 샤드 키 (shard keys)
- used to distribute the collection‟s documents across shards
- 클러스터들의 샤드들 간에 collection의 document를 어떻게 분산할 것인가 결정
- consists of a field or fields that exist in every document in the target collection
- 대상 집합의 모든 document에 존재하는 필드로 구성
- 컬렉션을 샤딩할 때, 샤드 키 선택 / 샤딩 후에는 변경 불가
- 여러 개의 shard 서버로 분할된 기준 필드 가르킴
- partition 과 load balancing 의 기준, mongodb 데이터 저장과 성능에 절대적인 영향
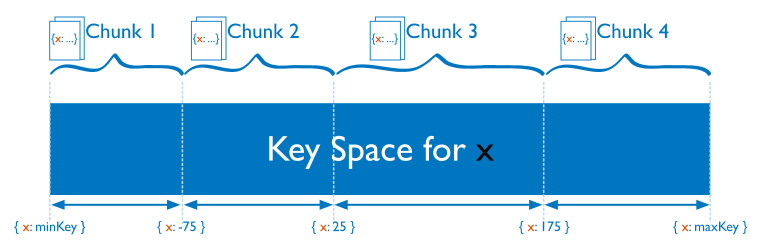
- 청크(chunks)
- a contiguous range of shard key values within a particular shard
- 특졍 샤드 내의 연속적인 샤드 키 값 범위
- each chunk has an inclusive lower and exclusive upper range based on the shard key.
- 각 청크에는 샤드 키를 기반으로 하는 포괄적인 하한 범위와 배타적인 상위 범위가 존재한다.
- default size : 64 MB
- 일정한 데이터양에 도달했을 때, 서버로 분할하는 단위
- balancer and even chunk distribution
- to achieve an even distribution of chunks across all shards in the cluster, a balancer runs in the background to migrate chunks across the shards when a shard contains too many chunks of a collection relative to other shards
- 클러스터의 모든 파편에 걸쳐 고르게 분포하기 위해 , 샤드에 다른 파편에 비해 너무 많은 컬렉션 덩어리가 포함되어 있을 때, 밸런서가 백그라운드에서 실행되어 파편에 걸쳐 청크를 마이그레이션(데이터의 이동, 서버에 균등하게 데이터를 재조정하는 과정) 한다.
3. Sharding 의 이점
• 읽기 및 쓰기 (Reads / Writes)
– read and write workloads can be scaled horizontally across the shards in the cluster by adding more shards.
– for queries that include the shard key or the prefix of a compound shard key, mongos can target the query at a specific shard or set of shards
– 샤드 클러스터의 샤드에 읽기 및 쓰기 워크로드를 분산시켜 각 샤드가 클러스터 작업의 서브 세트를 처리할 수 있도록
– 더 많은 샤드를 추가하여 읽기 쓰기 워크로드를 클러스터 전체에 수평적으로 확장 할 수 있게.
• 저장 용량 (Storage Capacity)
– each shard contains a subset of the total cluster data
– as the data set grows, additional shards increase the storage capacity of the cluster.
– 클러스터의 샤드에 데이터를 분산시켜 각 샤드가 전체 클러스터 데이터의 서브 세트를 포함.
– 데이터 세트가 커짐에 따라 , 추가 샤드가 클러스터의 스토리지 용량을 증가
• 고가용성 (High Availability)
– a sharded cluster can continue to perform partial read / write operations even if one or more shards are unavailable
– in production
– 클러스터는 한 개 이상의 shard를 사용할 수 없는 경우에도 부분 읽기 / 쓰기 작업을 계속 수행할 수 있음.
» 각 shard는 복제 세트로 구성 » config server는 최소 3개의 노드들로 구성된 복제 세트로 구성
4. Sharded and Non-Sharded Collections(샤드 및 비샤드 컬렉션)
• A database can have a mixture of sharded and unsharded collections
- 데이터베이스에 샤드와 비샤드 컬렉션이 혼합되어 있을 수 있음
• Sharded collections are partitioned and distributed across the shards in the cluster. Unsharded collections are stored on a primary shard
- 샤드 컬렉션이 샤드 컬렉션 안에서 분할과 분포되어있으면, 비샤드 컬렉션이 primary 샤드에 저장된다.
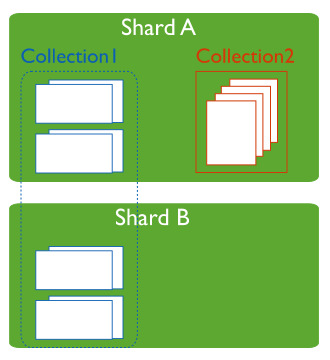
5. Connecting to a Sharded Cluster(샤드 클러스트에 연결)
• you must connect to a mongos router to interact with any collection in the sharded cluster
- 샤드 클러스터의 컬렉션과 상호작용하려면 mongos 라우터에 연결해야한다.
• you can connect to a mongos via the mongo shell or a MongoDB driver
- mongos를 사용하여 몽고쉘이나 몽고드라이버와 연결.

6. Two Sharding Strategies for distributing data across sharded clusters(샤드 클러스트에 데이터 배포하는 두가지 샤드 전략)
1) Ranged sharding(범위 샤딩)
• dividing data into several ranges based on the shard key values(샤드 키 값을 기준으로 데이터를 여러 범위로 구분)
• Each chunk is then assigned a range based on the shard key values (각 청크에는 샤드 키 기초한 범위가 할당)
• A range of shard keys whose values are “close” are more likely to reside on the same chunk
(값이 닫힘인 다양한 샤드 키가 동일한 청크에 더 많이 상주할 수 있음)
• The efficiency of ranged sharding depends on the shard key chosen(선택한 샤드키에 따라 범위 내 샤딩 효율성이 달라짐)
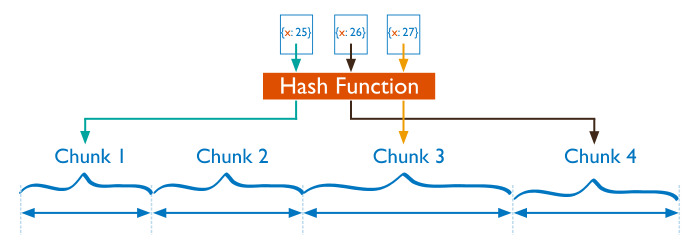
2)Hashed Sharding(해시 샤딩)
• computing a hash of the shard key field‟s value(샤드 키 필드 값의 해시 계산)
• Each chunk is then assigned a range based on the hashed shard key values.
(각 청크에는 해시된 샤드 키 값에 기초한 범위가 할당)
• While a range of shard keys may be “close”, their hashed values are unlikely to be on the same chunk.
Data distribution based on hashed values facilitates more even data distribution, especially in data sets where
the shard key changes monotonically
(다양한 샤드 키가 닫힘 일 수 있지만, 해시된 값은 동일한 청크 위에 있지 않는다 / 해시된 값에 기반한 데이터 배포를 통해 특히,
샤드 키가 단조롭게 변경되는 데이터 세트에서의 데이터 배포를 더욱 원활하게 수행)
7. setting up a local test
-> router(mongos) 1 + config server(mongod/ replica set 구성 필수) 1 + shard(mongod / replica set 구성 필수) 2

[1단계] 6개 노드에 대한 데이터 폴더 생성
• c:\data\configdb1 와 c:\data\configdb2
• c:\data\shard1a 와 c:\data\shard1b
• c:\data\shard2a 와 c:\data\shard2b
[2단계] config server 실행 및 복제 세트 구성
#1 -> c:\> mongod -–configsvr -–port 27500 -–dbpath c:\data\configdb1 --replSet crs
#2 -> c:\> mongod -–configsvr -–port 27501 -–dbpath c:\data\configdb2 --replSet crs
#3 -> c:\> mongo -–port 27500
> conf = {_id:”crs”, members:[{_id:0, host:”localhost:27500”},
{_id:1, host:”localhost:27501”}]}
> rs.initiate(conf) // 복제 세트 초기화
. . . .
crs:SECONDARY>
crs:PRIMARY>
[3단계] router(mongos) 실행
#4 -> c:\> mongos -–port 27100 –-configdb crs/localhost:27500
[4단계] shard #1 인스턴스 실행 및 복제 세트 구성
#5 -> c:\> mongod -–shardsvr -–port 27200 -–dbpath c:\data\shard1a --replSet srs1
#6 -> c:\> mongod -–shardsvr -–port 27201 -–dbpath c:\data\shard1b --replSet srs1
#7 -> c:\> mongo -–port 27200
> conf = {_id:”srs1”, members:[{_id:0, host:”localhost:27200”},
{_id:1, host:”localhost:27201”}]}
> rs.initiate(conf) // 복제 세트 초기화
. . . .
srs1:SECONDARY>
srs1:PRIMARY>
[5단계] shard #2 인스턴스 실행 및 복제 세트 구성
#8 -> c:\> mongod -–shardsvr -–port 27300 -–dbpath c:\data\shard1a --replSet srs2
#9 -> c:\> mongod -–shardsvr -–port 27301 -–dbpath c:\data\shard1b --replSet srs2
#10 -> c:\> mongo -–port 27300
> conf = {_id:”srs2”, members:[{_id:0, host:”localhost:27300”},
{_id:1, host:”localhost:27301”}]}
> rs.initiate(conf) // 복제 세트 초기화
. . . .
srs2:SECONDARY>
srs2:PRIMARY>
[6단계] shard #1과 shard #2를 shard cluster에 추가
• mongos에 연결 후 runCommand 명령으로 shard #1 & #2를 추가
• shard 추가 및 데이터 sharding은 db가 admin일 때만 가능
#11 -> c:\> mongo –-host localhost -–port 27100 . . .
mongos> use admin
mongos> db.runCommand({addShard:”srs1/localhost:27200, localhost:27201”, allowLocal:true})
mongos>
mongos> db.runCommand({addShard:”srs2/localhost:27300, localhost:27301”, allowLocal:true})
mongos>
mongos> sh.status()
[7단계] sharding 할 데이터 생성
#11 -> mongos>
mongos> use myshdb2
mongos> db.mycol.insert({“name”:“kim”, “year”:“1”})
mongos> . . . // 추가 삽입 n회
mongos> db.mycol.find().pretty()
mongos>
[8단계] 데이터 sharding 활성화
#11 -> mongos> use admin // 다시 admin db 선택
mongos> db.runCommand({“enablesharding”:“myshdb2”})
[9단계] 데이터 sharding
• 컬렉션 수준에서 sharding
• 여기서 shard key는 _id 필드로 지정
#11 -> mongos> db.runCommand({“shardcollection”:“myshdb2.mycol”, “key”:{“_id”:1}})
'Database Study > MongoDB' 카테고리의 다른 글
| [Mongodb]웹서비스컴퓨팅_11주차_(2) (0) | 2019.12.08 |
|---|---|
| [Mongodb]웹서비스컴퓨팅_10주차 (0) | 2019.12.03 |
| [Mongodb]웹서비스컴퓨팅_9주차 (0) | 2019.12.03 |
| [Mongodb]웹서비스컴퓨팅_7주차 (0) | 2019.10.15 |
| [Mongodb]웹서비스컴퓨팅_6주차 (0) | 2019.10.01 |