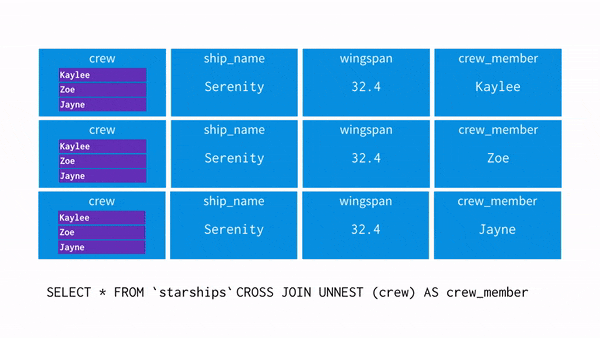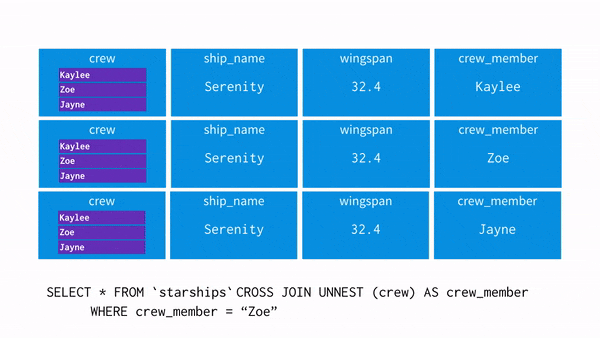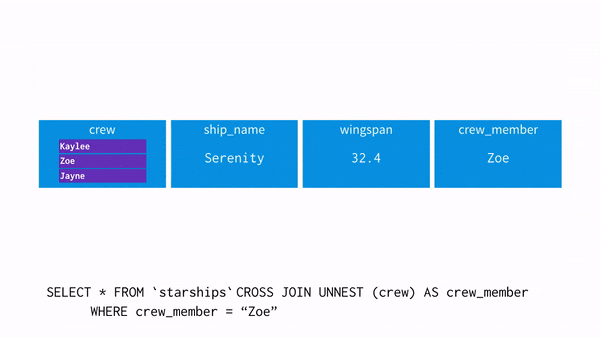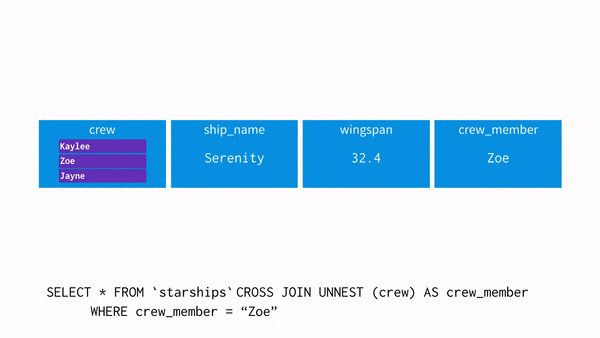
데이터 모델링?
주어진 개념으로 부터 논리적인 데이터 모델을 구성하는 작업.
설계 순서
1. 요구사항 파악 -> 2. 개념적 데이터 모델 설계 (ERD 작성) -> 3. 논리 모델링 -> 물리 모델링

모델링 3가지 요소
1. 업무가 관여하는 어떤 것(Things)
2. 어떤 것이 가지는 성격(Attributes)
3. 업무가 관여하는 어떤 것 간의 관계(Relationship)
좋은 데이터 모델의 요소
1. 완전성
2. 중복배제
3. 업무규칙
4. 데이터 재사용
5. 의사소통
6. 통합성
데이터 모델링 용어
| 논리 모델 | 물리 모델 |
| 엔티티(Entity) | 테이블(Table) |
| 속성, 어트리뷰트(Attribute) | 컬럼(Column) |
| 관계, 릴레이션(Relation) | 관계, 릴레이션(Relation) |
| 키 그룹(Key group) | 인덱스(Index) |
논리 모델링
- 어떤 정보를 객체화 할 것인가에 대한 규정(엔티티, 엔티티타입, 관계 정의)
- (EX) 업무를 분석하여 그에 대한 데이터 집합/ 관계를 중점적으로 표현하는 것
물리 모델링
- 실제 DBMS에서 생성될 테이블을 설계.
- 논리 모델링에서 도출된 각 엔티티 관계에 의해 나올 수 있는 테이블을 설계하거나
- (EX) many to many 관계에서 도출되는 table, super-sub 관계에서 도출되는 테이블 등)
- 관계에 대한 정의 (cascade 등등), index, 컬럼별 데이터 타입 및 제약 조건 등의 속성 정의 하여 정규화 실행
결과적으로는 모델링의 각종 이슈를 반영한 ERD를 포워딩 했을때 정확하게 데이터베이스가 생성되는 것을 보통 설계가 끝났다고 표현합니다.
ERD
:Entity Relationship Diagram / 데이터들의 관계 도표
ERD 규칙
- 엔티티(Entity) : 정보가 저장될 수 있는 사람, 장소, 사물, 사건 등 독립적인 존재. 즉, 테이블(학생, 과목, 수강, 사원, 부서)

- 두 개체의 관계 _선

- A 테이블의 PK 를 B테이블이 소유하면 -> A : 부모 / B : 자식
- 실선 : 부모 테이블의 PK를 자식 테이블이 가지고 있으며, 자식 테이블의 PK로 사용 시
- 점선 : 부모 테이블의 PK를 자식 테이블이 가지고 있으나, 자식 테이블의 PK로 미사용 시

Address 개체에서 address_id가 PK로 설정이 되어있는데 Store 개체가 address_id를 가지려 한다면,
이 때 식별자 관계에서는 FK를 PK로 설정(🔑)을 했고,
비식별자 관계에서는 일반 속성(🔹)으로 가지고 온 것을 확인 가능
참고로, FK를 PK로 지정할 때의
하나의 예시로 자식 테이블에서 할아버지/할머니 테이블을 참조할 때가 있을 수 있음.
상황에 따라 필요할 수도 있고 필요 없을수도?
- 속성(Attribute) : 엔터티의 성질, 분류, 수량, 상태 특성을 구체적으로 나타내는 세부 항목. 즉, 물리적 모델의 컬럼(열)을 말함.

※관계스키마 : 과목(과목코드, 과목내용, 과목명)
학생(이름, 학번, 주소, 전공, 취미)
(1) 속성유형
- 단순 속성(Simple Attribute) : 더 이상 작은 구성원소로 분해 할 수 없는 속성
- 복합 속성(Composite Attribute) : 몇 개의 기본적인 단순 속성으로 분해 할 수 있는 속성

- 다중 값 속성(Multivate Attribute) : 다중 값 속성은 한 엔터티에 대해서 여러 개의 값을 갖는 것으로써, 취미 속성

- 유도된 애트리뷰트(Derived Attribute) : 실제 값이 저장되어 있는 것이 아니라 저장된 값으로부터 계산해서 얻은 결과 값을 사용하는 애트리뷰트를 말한다.

(2) 주 식별자 / 비 식별자
- 주 식별자 : 식별 할 수 있는 유일한(Primary Key) 제약 조건을 갖는속성
ERD에서 실별자는 속성에 밑줄을 그어서 표현
예제) ERD

※ 관계스키마 : 사원(사원번호(PK), 이름, 주소, 주민번호)
취미
부서(부서코드(PK), 부서명)
(3) 관계 (Relation)
- 엔터티 사이의 연관성을 표현하는 개념
- 두 개의 엔터티 타입 사이의 업무적인 연관성을 논리적으로 표현
- ERD에서 엔터티들 사이에 관계
- 타입은 마름모를 사용하여 표현한 후 그 관계에 연관된 엔터티에 선으로 연결하여 표시

예제) ERD
- 소속 관계

- 수강 관계

(4) 유형
1. 카디날리티(Cardinality) : 관계의 대응 엔터티 수라고도 함
2. 카디날리티 표현방법 : 일대일(1:1), 일대다(1:N), 다대다(N:M)
- 두 개체의 관계 - 선의 끝Cardinality
Cardinality(차수)는 한 개체에서 발생할 수 있는 발생 횟수를 정의하며,
다른 개체에서 발생할 수 있는 발생 횟수와 연관.
1대1관계, 1대N관계, N대N 관계가 있음.
✔️ One-to-One Cardinality
1:1 관계에서는 아래와 같이 표기합니다.

One-to-One Cardinality
✔️ One-to-Many Cardinality
1:N 관계에서는 아래와 같이 표기합니다.

✔️ Many-to-Many Cardinality
N:M 관계에서는 아래와 같이 표기합니다.

Many-to-Many Cardinality
필수참여 조건
'|' 표시가 있는 곳은 반드시 있어야 하는 개체, 'O' 표시가 있다면 없어도 되는 개체

inventory 개체가 없어도 store 개체는 있을 수 있고, store 개체가 없다면 inventory 개체도 있을 수 없음.
'Database Study > SQL' 카테고리의 다른 글
| [SQL]LOCK이란? (0) | 2020.06.02 |
|---|---|
| [SQL]Join VS Union (1) | 2020.05.26 |
| [MySQL] CASE, COALESCE, IFNULL NULL 처리 (1) | 2020.03.11 |
| [MySQL]프로그래머스_입양 시각 구하기(2) (UNION/변수선언) (2) | 2020.03.10 |
| [Oracle DB]Join 종류 (0) | 2020.01.06 |