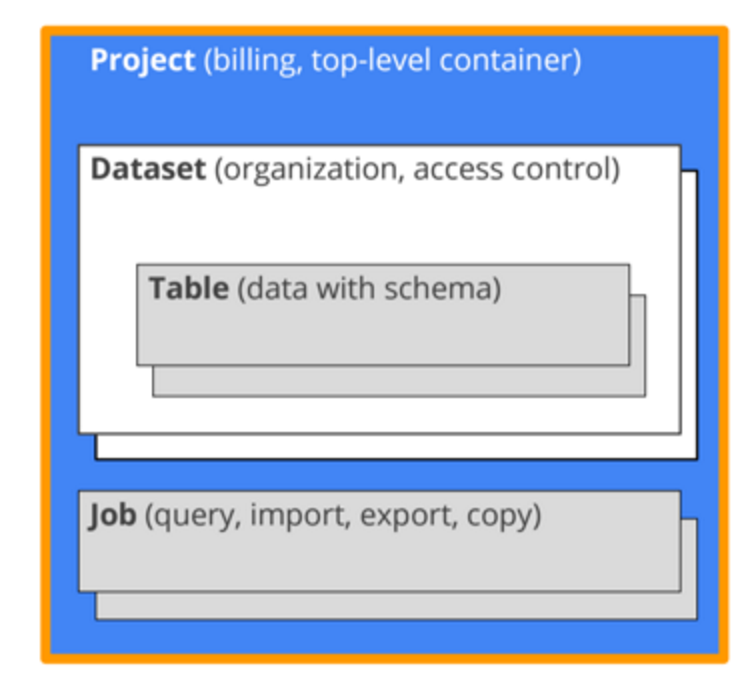
BigQuery는 구글 내부에서 방대한 양의 데이터를 SQL문을 통해서 분석하기 위해 개발한
Dremel이라는 프로젝트의 public implementation입니다.
Dremel 이전에는 하둡 기반의 클러스트를 구축하고, Map Reduce 방식을 통해 데이터 웨어하우스를 구축했다고 합니다
Dremel은 structured 데이터를 분산 저장하고 SQL문을 통해 빠르게 데이터를 분석하는데 특화되어 있습니다.
이를 통해, 데이터 분석가들이 다양한 쿼리문을 통해서 데이터에서 인사이트를 뽑아낼 수 있도록 도와줍니다.
한마디로 말하자면 빅쿼리란,
Dremel 프로젝트를 기반으로 구글 외부의 사용자들도 쓸 수 있도록 서버리스 클라우드 서비스로 만들어 공개한 것
입니다.
빅쿼리가 빠른 성능을 보여주는 것은 2가지의 특징 때문입니다.
1. Columnar Storage
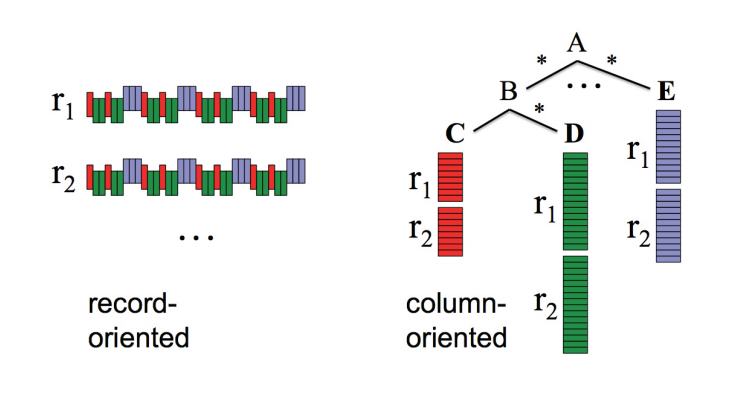
RDBMS는 레코드 단위로 데이터를 저장.
빅쿼리는 컬럼 단위로 데이터를 저장
즉, 같은 데이터 타입의 데이터들이 몰려서 저장되는 것 의미합니니다.
컬럼 단위로 데이터를 저장하는 장점은
- 트래픽 최소화 : 쿼리 사용 시 해당하는 컬럼만 조회하면 되기 때문에, 데이터 양이 방대해질 수록 트래픽을 최소화 할 수 있다.
- Higher Compression Ratio : 같은 데이터가 몰려 저장되어있기 때문에, 그 결과 압축하기에 더 용이.
2.Tree Architecture Distribution
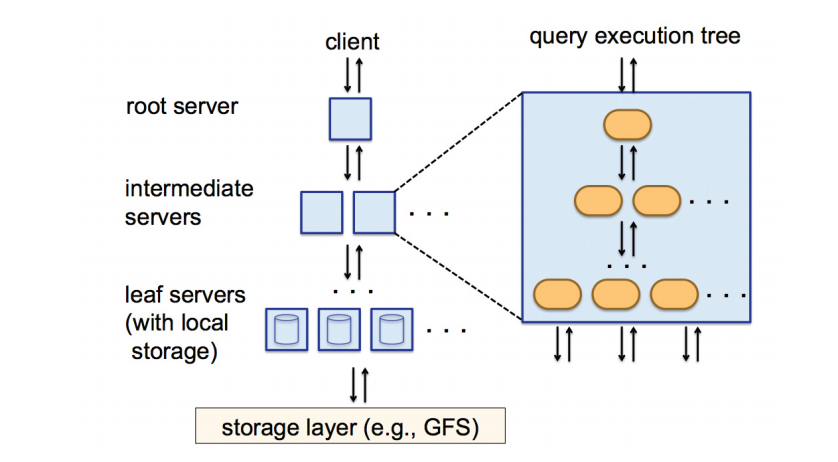
루트 서버 : 클라이언트 SQL 쿼리문 분석 -> 분산 머신에서 동작하는 수많은 작은 단위의 쿼리문 생성 -> Intermediate servers 전송
Intermediate server : 전달받은 쿼리를 더 작게 쪼개 -> leaf server로 전송
leaf servers : 실제 파일 시스템(빅 쿼리의 경우 Colossus)에 저장된 데이터를 읽어와서 쿼리 연산을 수행하고 결과를 부모 노드에게 전송
'Database Study > BigQuery' 카테고리의 다른 글
| [BigQuery]bq - 데이터 로드 (0) | 2020.09.04 |
|---|---|
| OLTP, OLAP (0) | 2020.08.31 |
| [BigQuery]표준 SQL 쿼리 구문 (0) | 2020.06.14 |
| [BigQuery] Datetime UTC 를 KST로 (0) | 2020.05.26 |
| [BigQuery]BigQuery란? (0) | 2020.05.25 |