
회사에서 데이터 추출에 쿼리를 짜야하는 일이 있었는데..
제가 짠 쿼리와 상사분께서 짠 쿼리의 성능차이가 엄청 난 것을 확인할 수 있었습니다.
(추출되는 데이터도 100G 정도 차이나고, 속도 또한 훨씬 향상된 쿼리였습니다. ㅜ.ㅜ)
제가 생각했을 때 근본적인 원인은
아직도 저는 빅쿼리를 사용할 때 RDB에서의 쿼리처럼 짜고 있는 것이라고 생각했습니다.
RDB에서는 OLTP, OLAP 페이지에서 확인할 수 있듯이,
하나의 레코드 안에 파일로서 저장하기 때문에 검색 시에 모든 데이터를 풀 스캔 하여야 합니다.
그러나, 빅쿼리는 컬럼 기반 저장소이기 떄문에, 각 칼럼 별로 다른 파일에 나누어 저장합니다.
즉, 제가 추출하고 싶은 각 컬럼을 행으로 집합 처리 한 후 join 조건의 쿼리를 날렸어야 하는 것인거죠..
빅쿼리의 집합처리 방법에 대해 알아보는 페이지가 될 것 같습니다.
참고로, 빅쿼리는 비정규화 되었을 때 성능이 가장 뛰어납니다.
- 비정규화를 위해 중첩 및 반복 열을 사용하며
- 중첩된 레코드를 사용할 때 장점은 아래와 같습니다.
- 빅쿼리 퍼포먼스 개선
- 데이터 저장 용량 효율
- 스키마가 바뀌어도 유연하게 대응 가능
참고 : https://zzsza.github.io/gcp/2020/04/12/bigquery-unnest-array-struct/
BigQuery ARRAY
- 문서 : cloud.google.com/bigquery/docs/reference/standard-sql/array_functions?hl=ko#generate_date_array
- 빅쿼리는 데이터 유형이 동일한 값으로 구성된 목록을 ARRAY(배열) 라 부릅니다.
- 파이선 LIST와 유사합니다.
- 하나의 행에 데이터 타입이 동일한 여러 값을 저장합니다.
- 빅쿼리 UI에서 배열로 보여줄 때 세로로 나열됩니다.
-
예시
SELECT
[1,2,3] AS array_sample, 1 AS int_value
UNION ALL
SELECT
[3,5,7] AS array_sample, 2 AS int_value
결과 : 행 1 안에 (1,2,3) 이 배열로서 출력되는 반면, 숫자값만 나열한 int_value는 1개만 볼 수 있습니다.
- ARRAY 생성 방법
-
대괄호 사용
SELECT [1, 2, 3] AS array_sample
-
ARRAY<타입> 사용
SELECT ARRAY<INT64>[1,2,3] AS int_array
-
GENERATE 함수 사용
-- GENERATE_ARRAY(시작, 종료, 간격) : python에서 range(start, end, step)과 동일하게 생성할 수 있습니다.
SELECT GENERATE_ARRAY(1, 10, 2) AS generate_array_data
- ARRAY_AGG 사용
-
테이블에 저장된 데이터를 SELECT 하고 ARRAY 로 묶고 싶은 경우 사용합니다.
- 옵션
- DISTINCT : 각각의 고유한 expression 값이 한 번만 결과에 집계됩니다.
- IGNORE NULLS : NULL 값이 결과에서 제외 / RESPECT NULLS : 지정되거나, 아무것도 지정되지 않으면 결과에 NULL 포함
- ORDER BY : 값의 순서 지정 (기본 정렬 방향은 ASC 입니다)
- LIMIT : 결과에서 expression 입력의 최대 개수를 지정합니다. 한도 n은 상수 INT64입니다.
-
예시
WITH programming_languages AS
(SELECT "python" AS programming_language
UNION ALL SELECT "go" AS programming_language
UNION ALL SELECT "scala" AS programming_language)
SELECT ARRAY_AGG(programming_language) AS programming_languages_array
FROM programming_languages

-
-
- ARRAY 내 접근
- 배열 N 번째 값을 가져오려면, OFFSET, ORDINARY 을 사용할 수 있습니다.
- OFFSET : 0 부터 시작
- ORDINARY : 1부터 시작
-
존재하지 않은 N을 지정하면 에러가 발생하는데, SAFE_를 앞에 붙여주면 NULL이 return 됩니다.
WITH programming_languages AS
(SELECT "python" AS programming_language
UNION ALL SELECT "go" AS programming_language
UNION ALL SELECT "scala" AS programming_language)
SELECT
ARRAY_AGG(programming_language)[OFFSET(0)] AS programming_languages_array,
ARRAY_AGG(programming_language)[ORDINAL(1)] AS programming_languages_array2
FROM programming_languages

- 배열 N 번째 값을 가져오려면, OFFSET, ORDINARY 을 사용할 수 있습니다.
BigQuery STRUCT
- 문서 : https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types?hl=ko#struct-type
- 구조체, BigQuery UI에서 RECORD로 표현됩니다.
- 각각의 유형(필수) , 필드 이름(선택사항) 이 있는 정렬된 필드의 컨테이너로
- Python 의 Dict 와 유사한 느낌입니다.
- Firebase에서 저장된 데이터를 볼 때 많이 사용합니다.
- STRUCT 생성 방법
-
소괄호 사용
SELECT (1, 2, 3) AS struct_test
-
STURCT<타입> 사용
SELECT STRUCT<INT64, INT64, STRING>(1, 2, 'HI') AS struct_test

-
ARRAY 안에 여러 STRUCT 사용하고 싶은 경우
SELECT
ARRAY(
SELECT AS STRUCT 1 as hi, 2, 3
UNION ALL
SELECT AS STRUCT 4 as hi, 5, 6
) AS new_array

-
BigQuery UNNSET
- 문서 : https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax?hl=ko#unnest
- 배열을 평면화해서 배열에 있는 값을 펴줄 때 사용합니다.
- NEST한 데이터를 UNNSET 하게 만드는 것과 같습니다.
- UNNSET 연산자는 ARRAY 를 입력으로 받고 ARRAY 의 각 요소에 대한 행이 한 개씩 포함된 테이블을 return 합니다.
- 각 행에 배열의 값을 뿌려주는 직관적인 예시가 있어 첨부하겠습니다 : https://medium.com/firebase-developers/using-the-unnest-function-in-bigquery-to-analyze-event-parameters-in-analytics-fb828f890b42
- 해당 데이터가 있습니다.

- crew = 'Zoe'를 추출하고 싶어 UNNSET을 사용해 데이터를 펴주는 과정을 시각화 하면 아래와 같습니다.
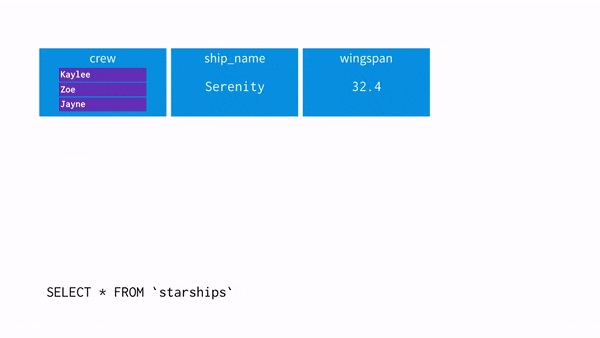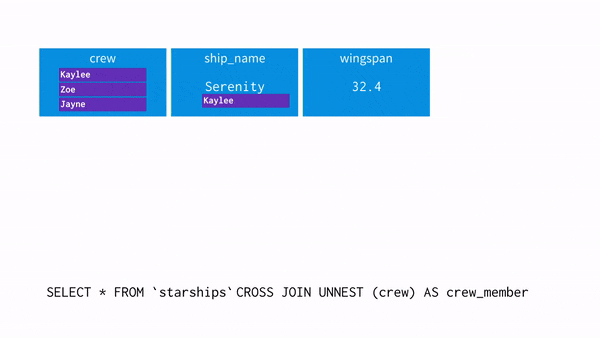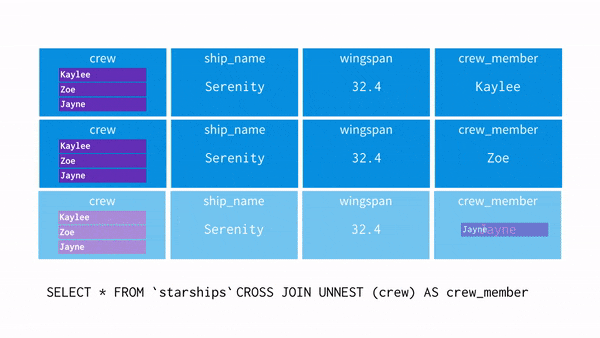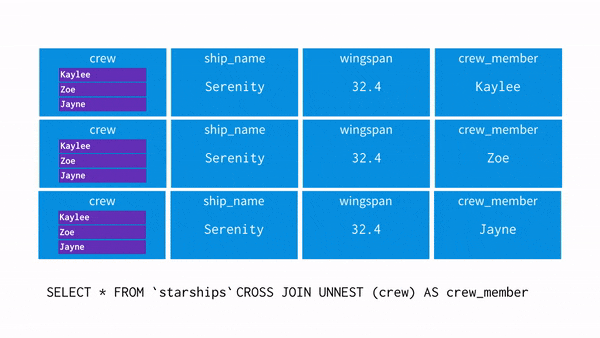
- WHERE 절로 Zoe 를 찾습니다.
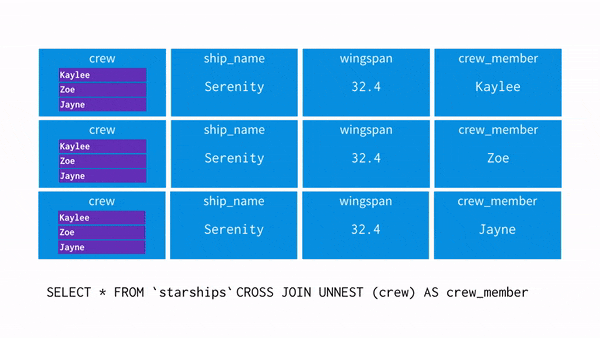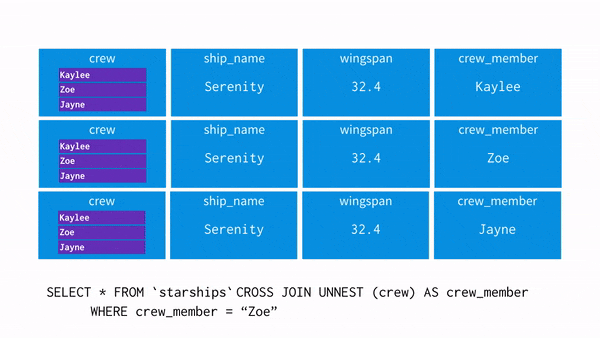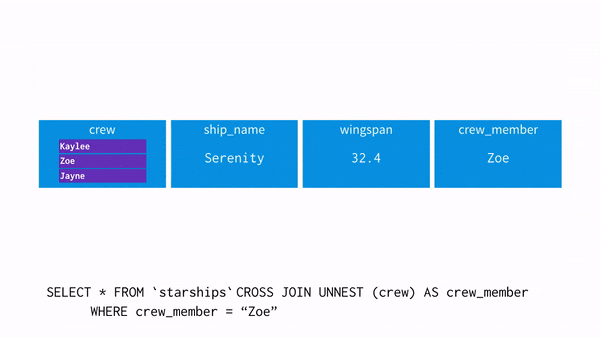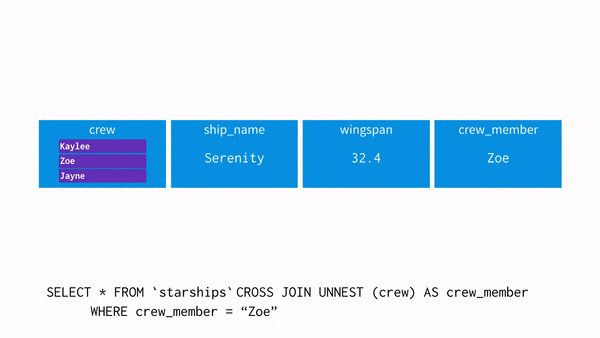
- 해당 데이터가 있습니다.
'Database Study > BigQuery' 카테고리의 다른 글
| [BigQuery]bq - 데이터 로드 (0) | 2020.09.04 |
|---|---|
| OLTP, OLAP (0) | 2020.08.31 |
| [BigQuery]표준 SQL 쿼리 구문 (0) | 2020.06.14 |
| [BigQuery] Datetime UTC 를 KST로 (0) | 2020.05.26 |
| [BigQuery]BigQuery Dremel (0) | 2020.05.26 |