1. Numpy 모듈 활용한 데이터 관리
- C언어로 구현된 파이썬 라이브러리
- 고성능 수치 계산 위해 제작
- 벡터, 행렬 연산에 있어 편리한 기능
- 데이터분석 라이브러리인 pandas와 matplotlib 의 기반으로 사용
cmd>> pip install numpy
#소스 코드에 import
import numpy as np #as np는 별명2. Numpy 모듈 사용하기
1) Array 생성, 조회
arr = np.array([[1,2,3], [4,5,6], [7,8,9]])
arr
>>>arr([[1,2,3],
[4,5,6],
[7,8,9])#array의 형태(크기)를 확인할 수 있다
arr.shape
>>>(3, 3)
#array의 자료형을 확인할 수 있다.
arr.dtype
>>>dtype('int64')2) Array 연산 가능
arr1 + arr2
arr1 / arr2
arr1 * arr2
arr1 - arr2
3) Array 생성, 조회
arr1 = np.arrange(10)
arr1
>>>array([0,1,2,3,4,5,6,7,8,9])
arr1[0]
>>>0
arr1[3:9]
#3번째 요소부터 8번째 요소
>>>arr1([3,4,5,6,7,8])
arr1[:]
>>>>>>array([0,1,2,3,4,5,6,7,8,9])
4)numpy 모듈의 주요 함수
- 난수 발생 함수 : np.random.rand(5,3)
- 각 성분 절대갑 계산 : np.abs(arr1)
- 각 성분 제곱 계산 : np.square(arr1)
- 각 성분의 소수 첫 번째 자리에서 올림한 값 계산 : np.ceil(arr1)
- 각 성분의 소수 첫 번째 자리에서 내림한 값 계산 : np.floor(arr1)
- 각 성분이 NaN인 경우 True를, 아닌 경우 False를 반환하기 : np.isnan(arr1)
- 각 성분이 무한대인 경우 True를, 아닌 경우 False를 반환하기 : np.isinf(arr1)
- 각 성분에 대해 삼각함수 값 계산(cos / cosh / sin / sinh/ tan / tanh) : np.cos(arr1)
- 전체 성분에 대해 오름차순 정렬 : np.sort(arr1)
- 전체 성분에 대해 내림차순 정렬 : np.sort(arr1)[::-1]
- 행 방향으로 오름차순으로 정렬 : np.sort(arr1, axis = 0)
5)Numpy 모듈 주요 통계 함수
- 전체 성분 합 계산 : np.sum(arr1)
- 열 간의 합을 계산 : np.sum(arr1, axis = 1)
- 행 간의 합을 계산 : np.sum(arr1, axis = 0)
- 전체 성분의 평균 계산 : np.mean(arr1)
- 행 간 평균 계산 : np.mean(arr1, axis = 0)
- 전체 성분의 표준 편차, 분산, 최소값, 최대값 계산(std, var, min, max) : np.std(arr1)
- 전체 성분의 최소값, 최대값이 위치한 인덱스를 반환 (argmin, argmax) : np.argmin(arr1)
- 맨 처음 성분 부터 각 성분까지의 누적합 / 누적곱 계산(cumsum , cumprod) : np.cumsum(arr1)
3. Pandas 모듈 활용한 데이터 관리
- 정형 데이터 관리 시 사용
cmd>> pip install pandas
1) 주요 데이터 유형

2) Series 유형 : 생성하기


3) Series 유형 : 조회하기
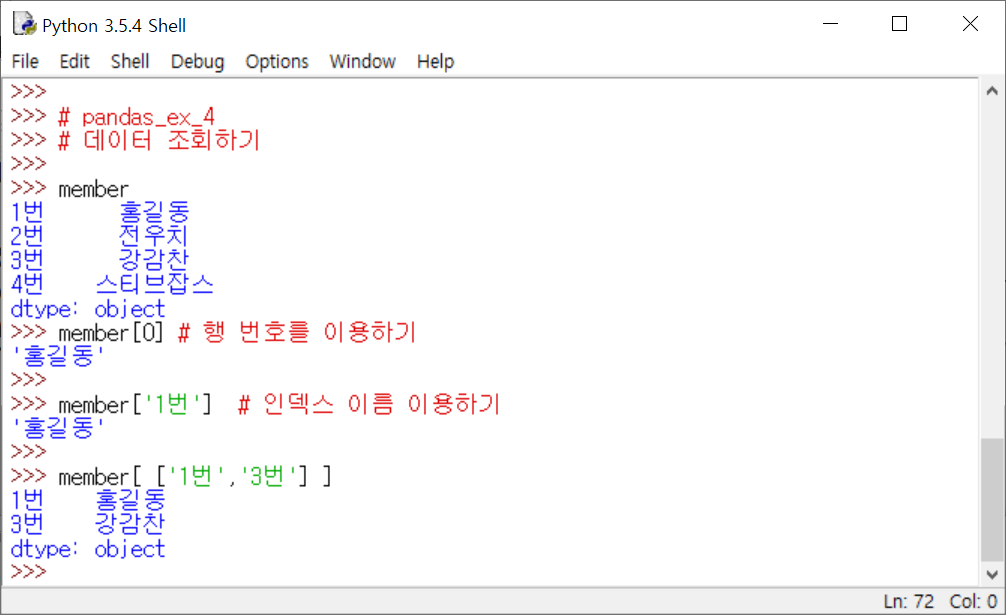
4) Series 유형 : 데이터 연산
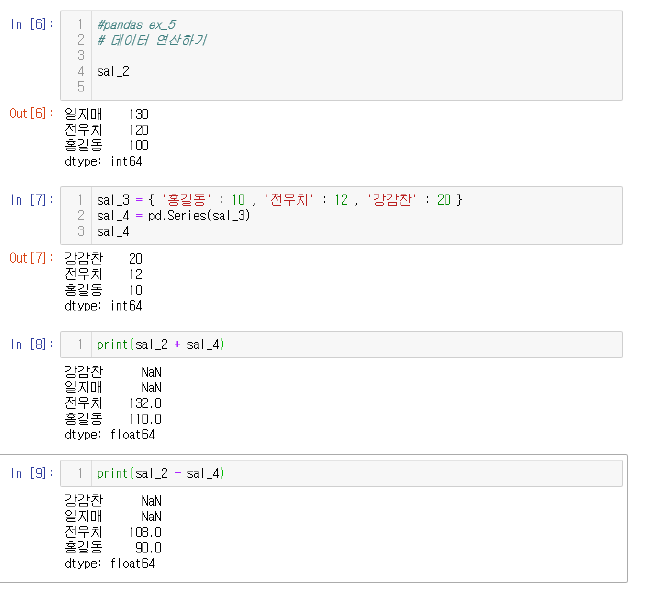
5) Dataframe 유형 : 생성


6) Dataframe 유형 : 정렬

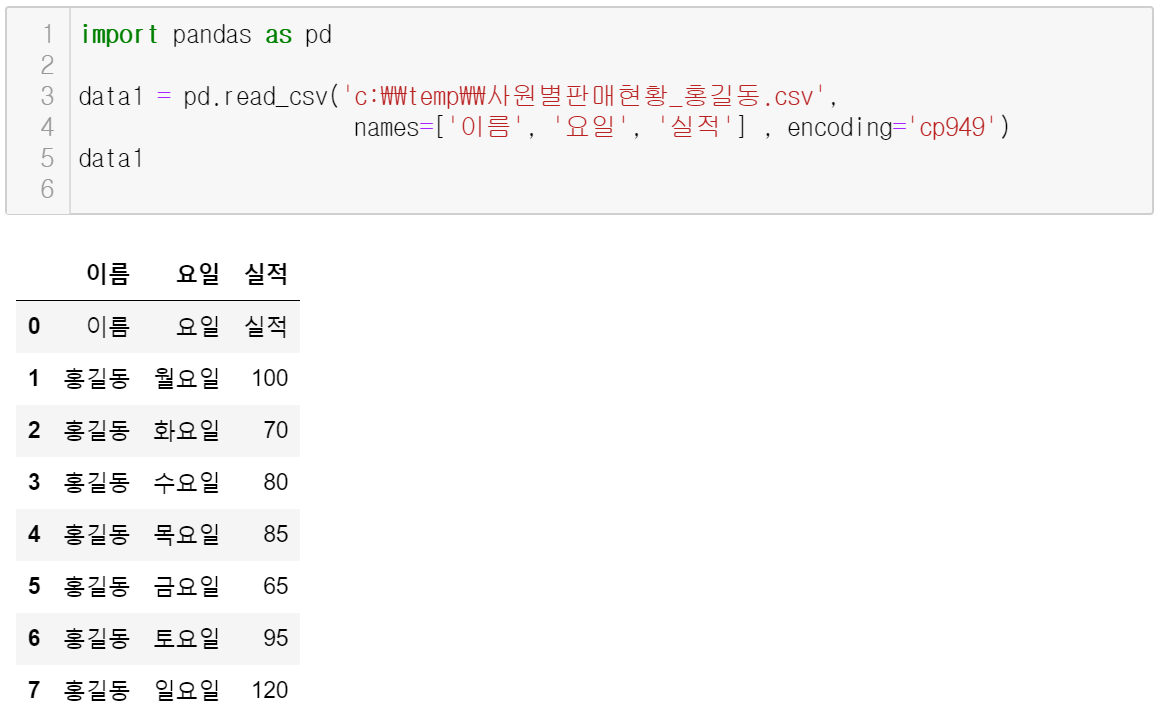
7) Dataframe 유형 : pandas에서 xls형식과 csv 형식 불러오기 (pip install xlrd 작업 후 )

8) DataFrame 유형 : 특정 컬럼 조회
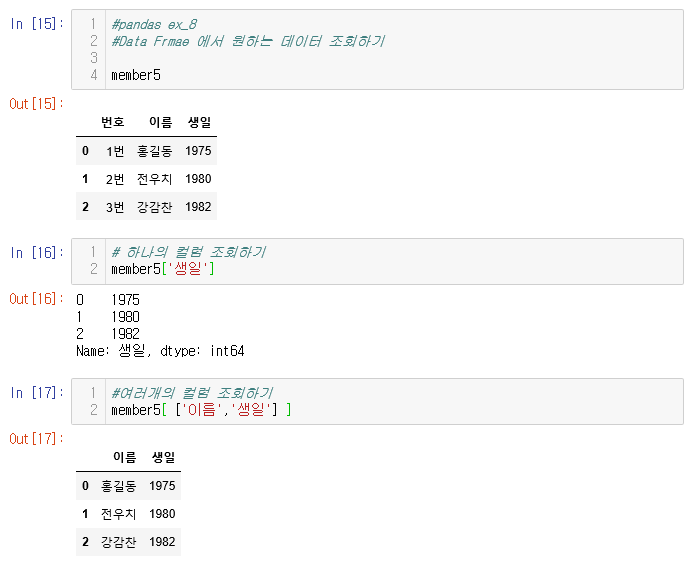
9) DataFrame 유형 : 원하는 조건으로 조회


10) Dafa Frame 유형 : 새로운 행과 열 추가하기


11) Data Frame 유형 : 행과 열 삭제하기


'Language Study > R' 카테고리의 다른 글
| matplotlib 모듈을 활용한 시각화 (0) | 2020.03.23 |
|---|---|
| Pandas - 행단위 데이터 읽기 (loc, iloc) (0) | 2020.02.16 |