반응형
1.이진 탐색 (Binary Search)
- 탐색할 자료 둘로 나누어 해당 데이터가 있을만한 곳 탐색
- 순차탐색과 비교해보면 이진탐색이 훨씬 더 효율적인 것을 알 수 있다
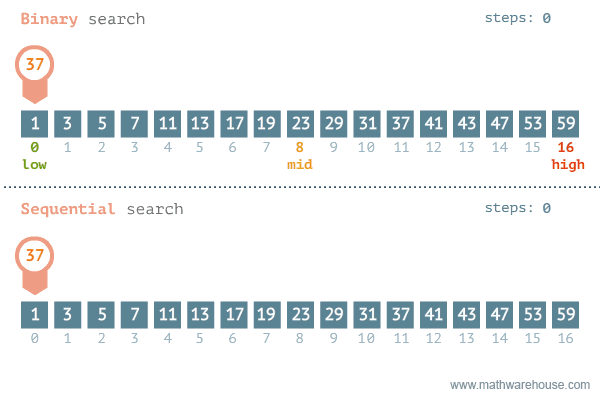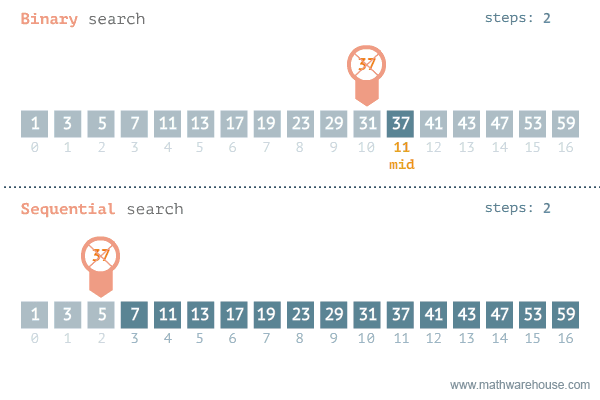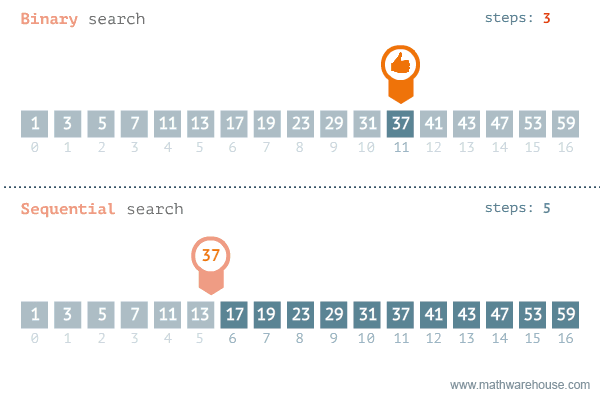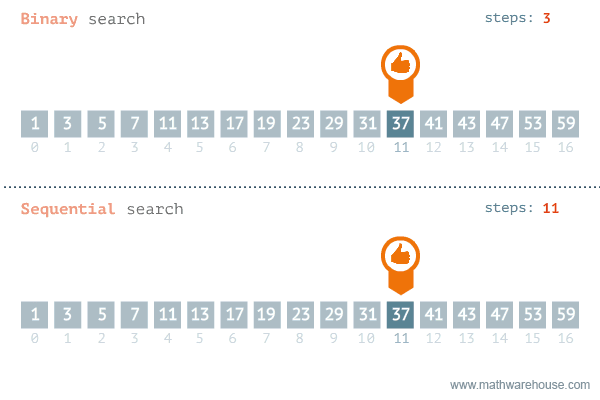
[저작자] by penjee.com
2. 분할정복 VS 이진 탐색
- 분할 정복 알고리즘(Divide and Conquer)
- 분할 : 문제를 하나 또는 둘 이상으로 나눔
- 정복 : 나눠진 문제가 충분히 작고, 해결이 가능하다면 해결 , 그렇지 않다면 다시 나눔
- 이진 탐색
- 이진 : 리스트를 2개의 서브 리스트로 나눔
- 탐색
- 검색할 숫자(search) > 중간값 이면, 뒷 부분의 서브 리스트에서 검색할 숫자 찾는다
- 검색할 숫자(search) < 중간값 이면, 앞 부분 서브 리스트에서 검색할 숫자 찾는다
3. 코드 생성
-> 이미 정렬되어 있는 상태에서 진행해야 함
- [2,3,8,12,20] 일 때,
- b_search(data_list , find_data) 함수 생성
- find_data : 찾는 숫자
- data_list : 데이터 리스트
- data_list의 중간값을 find_data와 비교
- find_data < data_list[mid] 이면
- 맨 앞부터 data_list[mid] 에서 다시 find_data 찾기
- find_data > data_list[mid] 이면
- data_list[mid] 부터 맨 끝까지 다시 find_data 찾기
- 그렇지 않으면, data_list[mid] = find_data 이므로
- return data_list[mid]
- find_data < data_list[mid] 이면
- b_search(data_list , find_data) 함수 생성
4. 알고리즘 구현
def b_search(data, search):
print(data)
if len(data) == 1 and search == data[0]:
return True
if len(data) == 1 and search != data[0]:
return False
if len(data) == 0:
return False
mid = len(data)//2
if search == data[mid]:
return True
else:
if search > data[mid]:
return b_search(data[mid+1:], search)
else:
return b_search(data[:mid], search)
import random
data_list = random.sample(range(100), 10)
>>>data_list.sort()
>>>[2, 5, 19, 21, 42, 47, 67, 72, 92, 98]
>>>b_search(data_list, 67)
>>>[2, 5, 19, 21, 42, 47, 67, 72, 92, 98]
>>>[67, 72, 92, 98]
>>>[67, 72]
>>>[67]
>>>True
5. 알고리즘 분석
-> n 개의 리스트를 매번 2로 나누어 1이 될 때까지 비교 연산 k회 진행하기 때문에
k + 1
반응형
'Algorithm Study > Algorithm' 카테고리의 다른 글
| 순차 탐색 (Sequential Search) (0) | 2020.02.04 |
|---|---|
| 퀵 정렬 (quick sort) 알고리즘 (0) | 2020.01.27 |
| 병합 정렬(merge sort) 알고리즘 (0) | 2020.01.20 |
| 동적 계획법 (Dynamic Programming)과 분할 정복 (Divide and Conquer) 알고리즘 (1) | 2020.01.13 |
| 재귀 용법(recursive call, 재귀 호출) (0) | 2020.01.09 |