<자바 문법 및 특징>
1. 자바 특징
현실 세계의 객체를 필드와 메서드로 정의한 Class 기반으로 실제 메모리가 잡혀 만들어진 부품과 같은 객체들을 조합해
전체 프로그램을 완성해 나가는 개발 기법
- oop : 객체 지향 언어
- 가비지 컬렉션에 의해 메모리 자동 관리
- 시스템에서 더이상 사용하지 않는 동적 할당된 메모리 블럭을 찾아 자동으로 다시 사용 가능한 자원 회수하는 것
- 시스템에서 가비지컬렉션을 수행하는 부분 : 가비지 컬렉터
- 멀티 쓰레드 지원
- JVM 위에서 동작하기 때문에 특정 OS에 종속적이지 않고 이식성이 좋으며 보안성이 좋다
- 다양한 오픈 라이브러리들이 존재한
- 추상화 : 객체의 공통적인 특징을 속성을 변수로 / 공통된 기능을 메소드로 만듬/일반메서드사용
- 추상 메서드 : 메서드의 정의부만 있고, 구현부는 있지 않는 메서드
- 추상 클래스 : 추상 메서드를 적어도 하나 이상 가지고 있는 클래스로 자식 클래스에서 오버라이딩(재정의)
필요한 추상메서드를 가지고 있기 때문에 객체화 할 수 없다.
- 캡슐화 , 은닉화 : 외부 객체에서 구현 방식 알 수 없도록 숨기고 별도로 접근할 수 있는 getter/setter 메서드를 통해 접근하는 방식
- 상속 : 부모 class를 자식이 접근할 수 있도록 물려 받는 방식
- 변수와 메소드를 그대로 쓰므로 코드 중복을 줄이고
- 객체 사용하는 클래스의 외부 관점으로 봤을 때, 묶어서 처리(upcasting)할 수 있으므로 효율적인 코드
- 다형성 : 부모 class 타입으로 해당 부모를 상속받는 여러 자식 class를 대입하는 성질
: 서로 다른 class로 부터 만들어진 객체이지만 같은 부모 class 타입으로 대입할 수 있는 성질- 오버로딩
- 하나의 클래스 내에 이름이 같은 여러 개의 메서드 정의
- parameter, return 타입 등이 다른데, 수행 내용이 본질적으로 동일 할 때 사용
- 오버라이딩
- 부모 클래스의 메소드를 자식 클래스에서 재정의
- 오버로딩
2. 객체와 클래스의 차이점
- 클래스 : 현실 세계의 객체 속성과 동작을 추려내 필드와 메서드로 정의한 것 "아직 메모리가 할당되지 않은 상태"
- 객체 : 클래스라는 설계도를 기반으로 실제 메모리가 잡힌 것을 의미,
이런 객체를 조합해 전체 프로그램을 완성해나가는 방식 OOP
3. Servlet , JSP
- Servlet : Container 가 이해할 수 있게 구성된 순수 자바 코드로만 이루어진 것(html in java)
- jsp : html 기반에 java코드를 블록화하여 삽입 (java in html)
4. GET, POST
- GET : 웹 브라우저가 웹 서버에 데이터를 요청할 때 사용
- 보안성이 떨어지고 , 길이 제한이 있다
- POST 보다 상대적으로 전송 속도가 post보다 빠름
- 웹 브라우저에서 웹 서버로 전달되는 데이터가 인코딩 되어 URL에 붙는다
- POST : 웹 브라우저가 웹 서버에 데이터를 전달하기 위해 사용
- HTTP 메시지로 넘어온 엔티티를 새로운 자원으로 등록 : 201 response
- 보안성이 높고, 속도가 get 보다 느리다
- 객체들의 값도 전송 가능
- PUT(식별자 포함하여 웹 서버에 데이터를 전달)과는 비슷하게 작동
5. Call by reference , Call by value
- Call by reference : 매개 변수가 원래 주소에 값을 저장
- Call by value : 주어진 값을 복사하여 처리
6. interface?
모든 메서드가 구현부가 없는 추상메서드, abstract 키워드 붙이지 않아도 자동으로 모든 메서드는 추상 메서드로 정의
- 인터페이스는 추상화와 다르게 메서드 선언만 가능
- 변수도 자동으로 final static 키워드가 붙는다.
7. 접근제한자
- public(접근 제한자가 없다/ 같은 프로젝트 내 어디서든 사용 가능 )
- protected(같은 패키지 내, 다른 패키지에서 상속받아 자손 클래스에서 접근)
- default (같은 패키지 내에서만 접근 가능)
- private (같은 클래스내에서만 접근 가능)
8. 소켓 통신 (tcp/udp)
- tcp (transmission control protocol)
- 연결형 서비스 제공
- 높은 신뢰성 보장
- 데이터 흐름 , 호잡 제어
- 3,4 -way handshaking(데이터 수신 여부 확인)
- 전이중, 점대점 서비스
- udp (user datagram protocol)
- 비연결형 서비스 제공
- 신뢰성 낮음
- 데이터 전송 순서 바뀜
- 데이터 수신 여부 확인 과정 없음
- tcp 보다 전송 속도가 빠름
9. Primitive type , Reference type
- Primitive type : 변수에 값 자체 저장
- 정수 / 실수 / 문자 / 논리형
- wrapper class (간단한 데이터를 객체로 만들어야 할 경우)를
통해 객체로 변형 가능 (int, char 제외하고 다른 자료형들은 맨 앞 알파벳을 대문자로 바꿔준다)
- Reference type : 메모리상에 객체가 있는 위치 저장
- class , interface , array
10. 세션, 쿠키 사용
- Session : 웹 브라우저의 캐시에 저장(서버에 저장)되어 브라우저가 닫히거나 서버에 삭제 시 사라진다
쿠키에 비해 보안성이 좋다 - Cookie : http 한계를 극복 / 인터넷 웹 사이트의 방문 기록을 남겨 사용자와 웹 사이트를 매개
아이디 , 비밀번호 / Client PC에 저장, 다른 사용자에 의해 임의 변경 가능 - 쿠키 대신 세션 사용하면 되는데 안하는 이유?
-> 세션에 저장하면 서버의 메모리가 과도하게 사용되어 서버에 무리가 감
11. 해쉬, 암호화
- 해쉬 : 단방향 암호화 / 복호화 불가능 / 데이터 보안에 중점
- 암호화 : 양방향 암호화 / 복호화 가능 / 통신 보안 중점
- Symmetric key (비밀키 : des / aes) / Asymmetric key(공개키 : dsa , rsa)
12. HTTP (Hyper Text Transfer Protocol)
- 웹브라우저와 웹서버가 서로 데이터를 주고 받을 때, 사용하는 규약
- 도메인 + URL(자원 위치) , 도메인 + URI(자원 식별자) 통해 요청, 서버가 요청에 따른 응답(.html) 해줌
- 특징
- Connectless + stateless : 클라이언트 이전 상태 알 수 없으므로(쿠키와 세션 필요)
- keep-alive : 지정된 시간 동안 연결 끊지 않고 연결된 상태 유지
웹 서버 연결 -> html 문서 다운로드 -> 필요한 img , js, css 다운 -> 연결 끊음
- http method
- GET : 정보를 요청하기 위해 사용 (READ)
- POST : 정보를 입력하기 위해 사용(CREATE)
- PUT : 정보를 업데이트 하기 위해 사용 (UPDATE)
- DELETE : 정보를 삭제하기 위해 사용 (DELETE)
- Request Header : 웹 브라우저가 웹 서버에 요청할 때 작성
- 유저가 서버 측에 요청한 정보
- Response Header : 웹 서버가 작성해서 웹 브라우저에 응답할 때 작성
- 유저의 요청(request)에 서버 측의 응답(response)정보
- https : http는 데이터 key와 , value 가 모두 표시되기 때문에 중요한 데이터 일 때 감춰야 함(HTTPS)
13. REST API
- 서버에 리퀘스트 할 때, 자원의 ID와 자원에 대한 처리(HTTP 메소드)를 포함하여 리퀘스트 되도록 하는 것
- 고유 자원에 대한 처리 URI로 나타낸 것
- 라우터 상에서 HTTP 메소드 (GET, POST, PUT, DELEE) 와 실제 자원에 대한 처리 (CRUD)를 맵핑 시켜야함
- HTTP method + 모든 개체 리소스화
+ URL 디자인(라우팅 : 클라이언트 요청에 대한 응답을 어떻게 이어줄 것인가 처리 / 자원에 대한 처리를 주소에 나타내지 않는다. )
14. 아파치, 아파치 톰캣
- 아파치 : HTTP 웹 서버(클라이언트의 요청을 기다리고 요청에 대한 데이터(정적 데이터)를 만들어서 응답하는 역할)
- 톰캣 : WAS(Web Application Server/ 서블릿 컨테이너) : 웹 서버와 웹 컨테이너 결합
- 다양한 기능을 컨테이너에 구현하여 다양한 역할을 수행
- 웹 컨테이너 : 클라이언트의 요청이 있을 때, 내부 프로그램을 통해 결과를 만들어내고 이것을 다시 클라이언트에게 돌려줌
- JSP, 서블릿 처리 / 서블릿 수명 주기 관리 / 요청 URL을 서블릿 코드로 매핑 / HTTP 요청 수신 및 응답 / 필터 체인
- 둘의 차이 : 웹 서버와 웹 어플리케이션 차이-> 단순 정적 데이터 (이미지나 단순 HTML)를 처리하는 서버라면 아파치
-> 동적 데이터 (DB 연결, 데이터 조작) 등 과 같은 처리 는 WAS
15. 동기, 비동기
- 동기 (synchronous)
- 요청과 그 결과가 한 자리에서 동시에 일어남
- A노드와 B 노드 사이의 작업 처리 단위(transcation)을 동시에 맞추겠다
- 장점 : 설계가 매우 간단, 직관적 / 단점 : 결과가 주어질 때 까지 아무것도 못하고 대기해야한다.
- 비동기 (asynchronous)
- 요청한 그 자리에서 결과가 주어지지 않음
- 노드 사이의 작업 처리 단위를 동시에 맞추지 않아도 된다.
- 장점 : 결과가 주어지는 데 시간이 걸리더라도 그 시간 동안 다른 작업할 수 있으므로 자원을 효율적으로 사용
단점 : 동기보다 복잡
16. 쓰레드 , 프로세스
- Process : 운영체제에서 실행 중인 하나의 프로그램(하나 이상의 쓰레드 포함)
- Thread : 프로세스 내에서 동시에 실행되는 독립적인 실행 단위 (stack메모리)
- 장점
- 빠른 프로세스 생성
- 적은 메모리 사용
- 쉬운 정보 공유
- 단점
- 교착상태(다중 프로그래밍 체제에서 하나 , 그 이상의 프로세스가 수행 할 수 없는 어떤 특정 시간 /
하나의 메서드를 여러 개의 쓰레드가 한번에 사용하게 되면 데드락 발생)
- 교착상태(다중 프로그래밍 체제에서 하나 , 그 이상의 프로세스가 수행 할 수 없는 어떤 특정 시간 /
- 장점
- Thread 와 Process 차이
- 이 프로세스 내에서 실행되는 각각의 일을 스레드
- 프로세스 내에서 실행되는 세부 작업 단위로 여러 개의 스레드가 하나의 프로세스를 이루게 됨
- 자바에서 main()메서드를 수행하기 위한 목적으로 제공된다 하여 main 쓰레드라 불린다
- 서로 메모리 공간을 공유하지 못해, IPC(Inter process communication) 방식이 필요
17.자바의 메모리 영역(간단하게 설명)
- 메서드 영역 : static 변수, 전역변수, 코드에서 사용되는 Class 정보 등.
- 코드에서 사용되는 class들을 로더로 읽어 클래스별로 런타임 필드데이터, 메서드 데이터 등을 분류해 저장
- 스택(Stack) : 지역변수, 함수(메서드) 등이 할당되는 LIFO(Last In First Out) 방식의 메모리
- 힙(Heap) : new 연산자를 통한 동작할당된 객체들이 저장되며, 가비지 컬렉션에 의해 메모리가 관리
18. 컬렉션 프레임워크
다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화 된 방법을 제공하는 클래스 집합
즉, 데이터를 저장하는 자료 구조, 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현
인터페이스를 사용해 구현
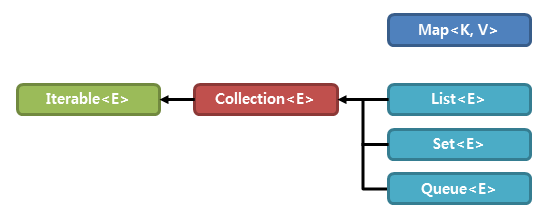
- List 인터페이스
- 순서가 있는 데이터 집합, 데이터 중복 허용
- vector , arraylist , linkedlist , stack , queue
- Set 인터페이스
- 순서가 없는 데이터 집합, 데이터 중복 허용 x
- hashSet, TreeSet
- Map 인터페이스
- 키와 값의 한 쌍으로 이루어지는 데이터 집합, 순서가 없음
- 키는 중복 허용 x, 값은 중복 가능
- haspmap , treemap, hashtable, properties
19. 제네릭
코드 블럭 내부에서 쓸 자료형을 외부에서 지정하는 기법
하지 않으면, 원하지 않는 자료형이 입력되었을 때 오류를 컴파일 시점에 잡아낼 수 없다
클래스<사용할 타입>
20. 자바 재귀함수
자기 자신을 호출하는 함수
원래 범위의 문제에서 더 작은 범위의 하위 문제를 먼저 해결함으로 원래 문제 해결
꼭 재귀호출이 끝나는 종료 조건이 있어야 한다
'Job Interview & etc > Java Web,Server' 카테고리의 다른 글
| Java 웹/서버 개발자 면접 질문(Spring) (0) | 2019.12.12 |
|---|---|
| Java 웹/서버 개발자 면접 질문(알고리즘) (0) | 2019.12.12 |
| Java / 웹 서비스 개발자 면접질문(기타 지식) (0) | 2019.12.05 |