2차원 평면 위의 점 N개가 주어진다. 좌표를 x좌표가 증가하는 순으로, x좌표가 같으면 y좌표가 증가하는 순서로 정렬한 다음 출력하는 프로그램을 작성하시오.
입력
첫째 줄에 점의 개수 N (1 ≤ N ≤ 100,000)이 주어진다. 둘째 줄부터 N개의 줄에는 i번점의 위치 xi와 yi가 주어진다. (-100,000 ≤ xi, yi ≤ 100,000) 좌표는 항상 정수이고, 위치가 같은 두 점은 없다.
출력
첫째 줄부터 N개의 줄에 점을 정렬한 결과를 출력한다.
알고리즘
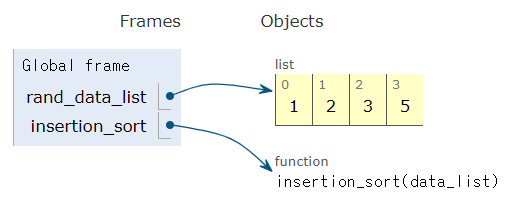
N = int(input())
dot = []
for _ in range(N):
x, y = map(int, input().split(" "))
dot.append((x,y))
dot_sort = sorted(dot, key=lambda x : (x[0], x[1]))
for x,y in dot_sort:
print(x,y)
첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000)이 주어진다. 둘째 줄부터 N개의 줄에는 숫자가 주어진다. 이 수는 절댓값이 1,000보다 작거나 같은 정수이다. 수는 중복되지 않는다.
출력
첫째 줄부터 N개의 줄에 오름차순으로 정렬한 결과를 한 줄에 하나씩 출력한다.
입력
5 5 2 3 4 1
출력
1 2 3 4 5
알고리즘
메모리 : 29440KB
시간 : 172ms
언어 : python 3
코드 길이 302B
n = int(input())
array = list()
for _ in range(n):
array.append(int(input()))
for i in range(n):
lowest = i
for j in range(i+1, n):
if array[lowest] > array[j]:
lowest = j
array[i], array[lowest] = array[lowest], array[i]
for i in array:
print(i)
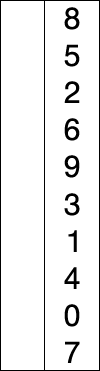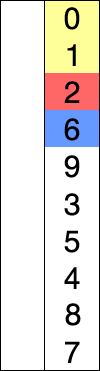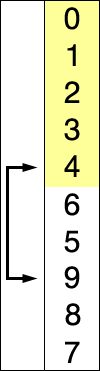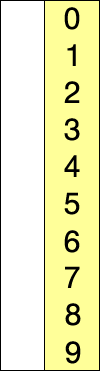
해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B값을 뒤 인덱스로 복사
이를 key 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동
2. 패턴 찾기
처음은 항상 인덱스(0)+1 에서 시작
data_list = [9, 3, 2, 5]
1회 : key 값 (9) , 인덱스(0) -1 보다 작으므로 => [9,3,2,5]
2회 : key 값 (3) , key -1 값(9) 이 3보다 작으므로 => [3,9,2,5]
3회 : key 값(2) , key -1 값(9) 보다 작고 -> key -2 값(2) 이 더 작으므로 => [2,3,9,5]
4회 : key 값(5), 9보다 작고, 3보다 크므로 => [2,3,5,9]
1. for stand in range(len(data_list)) 로 반복 2. key = data_list[stand] 3. for num in range(stand, 0, -1) 반복 - 내부 반복문 안에서 data_list[stand] < data_list[num - 1] 이면, - data_list[num - 1], data_list[num] = data_list[num], data_list[num - 1]
3. 알고리즘
def insertion_sort(data):
for index in range(len(data) - 1):
for index2 in range(index + 1, 0, -1):
if data[index2] < data[index2 - 1]:
data[index2], data[index2 - 1] = data[index2 - 1], data[index2]
else:
break
return data
def Selection_sort(data):
for stand in range(len(data) - 1):
lowest = stand
for index in range(stand+1, len(data)):
if(data[lowest]> data[index]):
lowest = index
data[lowest], data[stand] = data[stand], data[lowest]
return data
=> 로직을 적용 시, 한 번도 데이터가 교환되지 않는다면 이미 정렬된 상태므로 더 이상 로직을 반복 적용할
필요가 없다
==> 로직 한 회 끝날 때 마다 가장 큰 숫자가 뒤에서 1개씩 결정된다
리스트
1회
2회
3회
4회
1, 9, 3, 2
1, 3, 2, 9
1, 2, 3, 9
9, 7, 5, 3, 1
7, 5, 3, 1, 9
5, 3, 1, 7,9
3, 1, 5, 7, 9
1, 3, 5, 7, 9
4. 알고리즘
<프로토 타입> 1. for num in range(len(data_list)) 반복 2. swap = false // 교환되어있는지 확인, false 가 기본값이여야 아래 for문에서 swap 이 멈춰야 알고리즘 종료 3. 반복문 안에서 , for index in range(len(data_list) - num - 1) 를 n-1번 반복해야한다 //num 을 빼는 이유는 data_list에서 로직이 돌면 맨 뒤에 가장 큰 값이 고정되기 때문에 4. 반복문안의 반복문 안에서, if data_list[index] > data_list[index + 1] 이면 5. swap 시켜야한다 6. 더이상 swap 되지 않고 false 값이 나오면 break
def bubblesort(data):
for index in range(len(data) - 1):
swap = False
for index2 in range(len(data) - index - 1):
if data[index2] > data[index2 + 1]:
data[index2], data[index2 + 1] = data[index2 + 1], data[index2]
swap = True
if swap == False:
break
return data
두 수의 최소공배수(Least Common Multiple)란 입력된 두 수의 배수 중 공통이 되는 가장 작은 숫자를 의미합니다. 예를 들어 2와 7의 최소공배수는 14가 됩니다. 정의를 확장해서, n개의 수의 최소공배수는 n 개의 수들의 배수 중 공통이 되는 가장 작은 숫자가 됩니다. n개의 숫자를 담은 배열 arr이 입력되었을 때 이 수들의 최소공배수를 반환하는 함수, solution을 완성해 주세요.
제한 사항
arr은 길이 1이상, 15이하인 배열입니다.
arr의 원소는 100 이하인 자연수입니다.
입출력 예
arr
result
[2,6,8,14]
168
[1,2,3]
6
나의 코드
import java.util.Arrays;
class Solution {
public int solution(int[] arr) {
Arrays.sort(arr);
int lcm = arr[0] * arr[1] / gcd(arr[0], arr[1]);
for (int i = 2; i < arr.length; i++) {
lcm = lcm * arr[i] / gcd(lcm, arr[i]);
}
return lcm;
}
public static int gcd(int small, int big) {
while (small != 0) {
int nmg = big % small;
big = small;
small = nmg;
}
return big;
}
}
다른사람 코드
// 문제가 개편 되었습니다. 이로 인해 함수 구성이 변경되어, 과거의 코드는 동작하지 않을 수 있습니다.
// 새로운 함수 구성을 적용하려면 [코드 초기화] 버튼을 누르세요. 단, [코드 초기화] 버튼을 누르면 작성 중인 코드는 사라집니다.
class NLCM {
public long nlcm(int[] num) {
long answer = num[0],g;
for(int i=1;i<num.length;i++){
g=gcd(answer,num[i]);
answer=g*(answer/g)*(num[i]/g);
}
return answer;
}
public long gcd(long a,long b){
if(a>b)
return (a%b==0)? b:gcd(b,a%b);
else
return (b%a==0)? a:gcd(a,b%a);
}
public static void main(String[] args) {
NLCM c = new NLCM();
int[] ex = { 2, 6, 8, 14 };
// 아래는 테스트로 출력해 보기 위한 코드입니다.
System.out.println(c.nlcm(ex));
}
}