반응형
쿼리문 예시 보기 좋은 사이트 입니다. 참고 ~
https://docs.mongodb.com/manual/tutorial/query-documents/
https://docs.mongodb.com/manual/reference/sql-comparison/
1. 중첩된 문서를 포함하는 문서에 대한 질의(embedded document 추가 예시)
> db.myCol.insert( { “name”: “kim”, “address”:{ “city”:“seoul”, “gu”:“nowon” }
- 중첩된 문서 전체를 비교하는 질의
> db.myCol.find( {“address”:{“city”:“seoul”, “gu”:“nowon”} })
- 중첩된 문서의 특정 필드 값 비교 질의
- 필드 구분자로 '.' 을 사용
- 반드시 ""로 묶어야 함
// partial match (중첩된 문서의 일부 필드만 일치 여부 비교)
> db.myCol.find( {“address.city”:“seoul”})
> db.myCol.find( {“address.gu”:”nowon”, “address.city”:“seoul”})
> db.myCol.find( {“address.gu”:”nowon”})
- 배열을 포함하는 문서에 대한 질의1
> db.myCol.insertMany( [
{“name”: “cho”, “hobby”:[“football”, “swimming”]},
{“name”: “kim”, “hobby”:[“game”, “swimming”, “football”]}
])
- 배열 전체 비교 질의
- 완전 일치
// exact match (배열 요소의 값, 개수, 순서까지 일치)
> db.myCol.find( {“hobby”:[“football”, “swimming”] })
- 부분 일치(주어진 값들의 순서 상관 없이 배열 요소로 존재하는지 질의)
// partial match
> db.myCol.find( {“hobby”:{ $all:[“football”, “swimming”] } })
- 배열 포함하는 문서에 대한 질의2
> db.myCol.insertMany( [
{ “name”: “joo”,
“hobby”:[“football”, “swimming”],
“points”:[25, 28, 30, 34] },
{“name”: “park”,
“hobby”:[“game”, “football”, “swimming”],
“points”:[27, 30, 40] }
])
- 배열의 특정 요소(들)에 대한 질의
// 배열 hobby의 요소 값 중에 “swimming”을 내용으로 가지는 문서 검색
> db.myCol.find( {“hobby”:“swimming” })
// 배열 points의 요소 값 중에 하나라도 34보다 큰 값을 가지는 문서 검색
> db.myCol.find( {“points”:{$gt:34} })
// 배열 hobby의 두 번째 요소 값을 “swimming”으로 가지는 문서 검색
> db.myCol.find( {“hobby.1”:“swimming” })
// 크기가 3인 배열 hobby를 포함하는 문서 검색
> db.myCol.find( {“hobby”:{$size:3} })
- 배열을 포함하는 문서에 대한 질의3
> db.myCol.insertMany( [
{ “name”: “joo”, “points”:[25, 27] },
{ “name”: “min”, “points”:[14, 21] },
{ “name”: “yoo”, “points”:[19] }
])
- 배열 요소(들)에 대한 여러 개의 조건 가지는 질의
// 배열 points의 요소들 중에 (15보다 큰 조건만을 만족하는 요소도 있으면서 20보다 작은 조건을 만족하는 또 다른 요소도 있는 문서) 또는 (한 요소가 15보다 크면서 20보다 작은 조건을 모두 만족)하는 문서 검색
> db.myCol.find( {“points”:{$gt:15, $lt:20} })
// 배열 points의 요소들 중에 적어도 하나라도 (21보다 크고 26보다 작은 조건을 모두 만족)하는 요소를 가지는 문서 검색
> db.myCol.find( {“points”:{$elemMatch:{$gt:21, $lt:26}} })
- 배열을 포함하는 문서에 대한 질의 4
- 배열의 요소 값이 문서인 경우 질의 (심화 질의)
> db.myCol.insertMany( [
{ “name”:“cho”,“friends”:[{“name”:”ko”},{“name”:”joo”,“age”:24}] },
{ “name”:“yoo”,“friends”:[{“name”:”jon”, “age”:20},{“name”:”je”}] } ] )
Q1) 이름이 joo이고 나이가 24인 친구를 가지고 있는 사람의 이름은?
Q2) 나이가 22살 이하인 친구를 가지고 있는 사람의 이름은?
Q3) 첫 번째 친구의 나이가 20인 친구를 가지고 있는 사람의 이름은?
2. Indexing(인덱스)
- 몽고 디비 쿼리에서 효율적인 실행을 지원
-> 인덱싱이 없이 몽고디비는 콜렉션 스캔을 실행하여야 한다.
-> ex) 쿼리문에 일치하는 도큐먼트 선별하기 위해 컬렉션 내의 모든 도큐먼트를 스캔해야한다 - 인덱스 : 콜렉션의 데이터셋의 작은 일부를 저장하고 있는 특별한 데이터 구조
-> 인덱스는 특정 필드 또는 필드 세트의 값을 인덱스에 지정된 필드 값 순서로 저장
-> 컬렉션내의 임의의 문서를 빠르게 접근하도록 하는 자료구조
->인덱스는 데이터 파일과는 별도의 파일에 저장됨
->검색 속도를 향상시키나 인덱스 저장 공갂 필요
-> 삽입, 삭제, 수정 연산의 속도 저하 - 인덱스의 구조
-> 엔트리 구조 : < 탐색 키 필드, 문서에 대핚 포인터 >
->엔트리들은 탐색 키 필드 값의 오름차순으로 정렬되어 있음
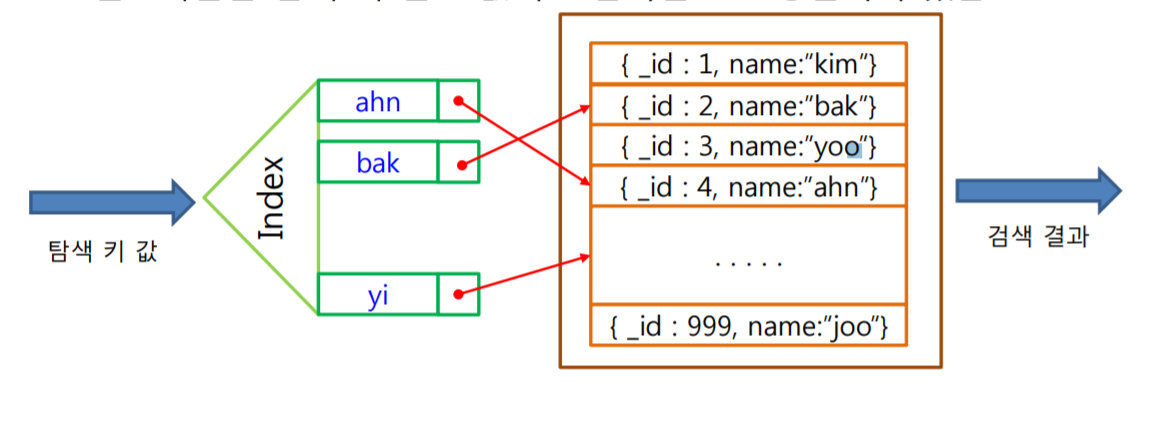
- 다단계 인덱스 : B, B+ 트리 사용

1) ensureIndex() 메서드
db.COLLECTION_NAME.ensureIndex({KEY : 1})
-> key 는 색인을 작성하려는 필드의 이름 / 1은 오름차순 / 내림차순으로 인덱스를 만들려면 -1
-> 여러 필드에 인덱스를 만들려면 여러 필드를 전달할 수 있다.
>db.mycol.ensureIndex({"title" : 1})
>db.mycol.ensureIndex({"title":1,"description":-1}) //여러 필드 전달
- ensureIndex() 메소드는 옵션 목록도 허용합니다.
| PARAMETER | TYPE | DESCRIPTION |
| background | boolean | 인덱스를 빌드해도 다른 DB 활동을 차단하지 않도록 백그라운드에서 인덱스를 빌드한다. 백그라운드에서 빌드하려면 TRUE / 기본값은 FALSE |
| unique | boolean | 인덱스 키가 인덱스의 기존 값과 일치하는 문서 삽입을 허용하지 않도록 고유 인덱스를 생성/ 고유 인덱스를 작성하려면 TRUE 지정 / 기본값은 FALSE |
| name | string | 인덱스의 이름/ 지정되지 않은 경우 mongodb는 인덱스화 된 필드의 이름과 정렬 순서를 연결하여 인덱스 이름을 생성 |
| dropDups | boolean | 중복될 수 있는 필드에 고유 인덱스를 작성 / mongodb는 키의 첫번째 항목만 인덱스화하고 해당 키의 후속 항목이 포함된 콜렉션에서 모든 문서를 제거 / 고유 인덱스를 작성하려면 true를 지정/ 기본값은 false |
| sparse | boolean | true인 경우 인덱스는 지정된 필드가 있는 문서만 참조 / 이 인덱스는 공간을 덜 사용하지만 일부 상황(정렬..) 에서 다르게 동작 / 기본값 false |
| expireAfterSeconds | Integer | mongodb가 콜렉션에서 문서를 보유하는 기간을 제어하기 위해 TTL 값을 초 단위로 지정 |
| v | Index Version | 색인 버전 번호 / 기본 인덱스 버전은 인덱스 작성시 실행중인 mongodb 버전에 따라 다름 |
| weights | Document | 가중치는 1~99,999 범위의 숫자, 점수를 기준으로 다른 색인화 된 필드에 대한 필드의 중요성 나타냄 |
| default_language | string | 텍스트 인덱스의 경우 중지 단어 목록과 형태소 분석기 및 토크 나이저에 대한 규칙을 결정하는 언어 / 기본값 english |
| language_override | string | 텍스트 인덱스의 경우 기본 언어를 대체 할 언어를 포함하는 문서의 필드 이름 지정 / 기본값은 언어 |
2. 커서(5주차 추가 메뉴얼)
- 커서의 활용
- find() 메소드 : 검색된 문서 집합에 대한 커서 반환
- var 타입의 번수 사용하지 않는 경우
// mongo 쉘에서는 반환 결과를 변수에 할당하지 않으면
// 커서가 자동으로 20번 반복되어 문서 20개를 자동 출력 후 대기
// “it” 입력하면 커서 반복
> db.myCol.find()
- var 타입의 변수 사용하는 경우
- 반환된 문서 집합에 대해 커서를 수동으로 반복하여 개별적 문서 접근
> var myCursor = db.myCol.find()
> myCursor // 커서 20번 반복 -> 20개 문서 출력 후 대기
> var myCursor = db.myCol.find()
> while (myCursor.hasNext()) {
print(tojson(myCursor.next()));
// printjson(myCursor.next());
}
- 커서 활용
- 검색 결과의 문서 개수 출력
> db.myCol.find.count()
> var res = db.myCol.find.count()
> res
3. Index 메소드
인덱스 생성 메소드 //createIndex()
db.컬렉션명.createIndex(<키> , <옵션>)
// <키>는 문서 형식 {키:1 or -1, ... }으로 명세 (1:오름, -1:내림)
// <옵션>도 문서 형식 {키:값, ... }으로 명세
- 단일 / 복합 인덱스 (single / compound index) 생성
db.mycol.createIndex({"age" : 1})
//단일 키 인덱스(하나의 필드만 사용)
db.mycol.createIndex({"deptname" : 1, "year" : -1})
//복합 키 인덱스 (2개 이상의 필드 사용)
//키의 순서 중요
- 다중키 인덱스(multikey index)
- 필드의 값이 배열(예, 취미)인 경우 생성되는 인덱스 (별도 지정 불필요)
- 배열의 각 요소 마다 인덱스 엔트리 유지
- 같은 배열에서 생성된 여러 엔트리들을 동일한 문서 참조(포인트)
- 인덱스 생성시 인덱스명 작명
- 시스템이 기본적으로 주는 기본 이름 대신 의미 있는 이름으로 작명
- 기본 이름 : 인덱스 키 (필드) 와 정렬 기준(1 / -1) 값을 조합하여 작명
db.mycol.createIndex({username : 1} , {name : "userinfo_idx"})
- 고유 인덱스 (unique index)
- 컬렉션 내 동일한 인덱스 필드 값을 갖는 문서 중복 불가
- _id 필드에 대한 고유 인덱스는 자동으로 생성
- 문서 삽입 이전에 인덱스를 생성하는 것 좋음
db.mycol.createIndex({username : 1}, {unique : true})
- 희소 인덱스(sparse index)
- 인덱스 키 필드를 포함하는 문서에 대해서만 인덱스 엔트리를 유지
- oop, 밀집 인덱스(dense index)
- 모든 문서에 포함되지 않는 필드에 인덱스를 생성할 경우 유용
db.mycol.createIndex({fax : 1}, {sparse : true, unique : true})
인덱스 정보 확인 메소드 //getIndexes()
- 한 컬렉션 내에 생성된 모든 인덱스 정보를 문서 배열로 반환
db.컬렉션명.getIndexes() 또는 db.컬렉션명.getIndexSpecs()
> db.mycol.getIndexes() [
{
“v”:1, // 인덱스 버전 번호 (미활용)
“key”:{“username”:1}, // 인덱스 키 정보
“ns”:“mycol.username”, // 네임 스페이스
“name”:“username_1” // 인덱스명
},
{ . . . }
]
인덱스 제거 메소드 //dropIndex()
- 컬렉션 내의 특정 인덱스 제거
- <인덱스_정보> : 문서 형식으로 명세 : {"인덱스명" : 1 또는 -1}
db.컬렉션명.dropIndex("인덱스명" 또는 <인덱스_정보>)
> db.mycol.dropIndex(“stdinfo_idx”)
> db.mycol.dropIndex(“username_1”)
> db.mycol.dropIndex({“username”:1})
- 여러 개의 인덱스 제거 메소드
- 해당 컬렉션에 대한 모든 인덱스 제거 (단, _id 인덱스는 제외)
db.컬렉션명.dropIndexes()
반응형
'Database Study > MongoDB' 카테고리의 다른 글
| [Mongodb]웹서비스컴퓨팅_9주차 (0) | 2019.12.03 |
|---|---|
| [Mongodb]웹서비스컴퓨팅_7주차 (0) | 2019.10.15 |
| [Mongodb]웹서비스컴퓨팅_5주차 (0) | 2019.09.24 |
| [Mongodb]웹서비스컴퓨팅_4주차 (0) | 2019.09.17 |
| [Mongodb]웹서비스컴퓨팅_3주차 (0) | 2019.09.10 |