반응형
1. 선택정렬
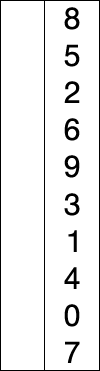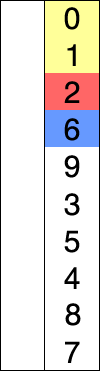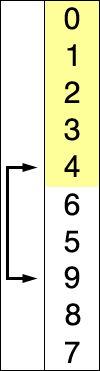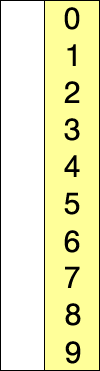
- 주어진 데이터 중 최소 값을 찾음
- 해당 최소값을 데이터 맨 앞에 위치한 값과 교체
- 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복
2. 패턴 찾기
- data_list = [9,3,2,1]
- 1회 : 1, 3, 2, 9
- 2회 : 1, 2, 3, 9
- 3회 : 1, 2, 3, 9
| 0 | 1 | 2 | 3 |
비교데이터 인덱스 |
비교시작 데이터 인덱스 |
비교 끝 데이터 인덱스 |
| 5 | 4 | 3 | 1 | |||
| 1 | 4 | 3 | 5 | 0 | 1 | 3 |
| 1 | 3 | 4 | 5 | 1 | 2 | 3 |
| 1 | 3 | 4 | 5 | 2 | 3 | 3 |
- for stand in range(len(data_list) - 1) 로 반복
- lowest = stand 로 놓고, //기준점이 맨 앞 최소값이니까
- for num in range(stand, len(data_list)) stand 이후부터 반복
- 내부 반복문 안에서 data_list[lowest] > data_list[num] 이면,
- lowest = num // 교환 해줌
- data_list[num], data_list[lowest] = data_list[lowest], data_list[num]
3. 알고리즘
def Selection_sort(data):
for stand in range(len(data) - 1):
lowest = stand
for index in range(stand+1, len(data)):
if(data[lowest]> data[index]):
lowest = index
data[lowest], data[stand] = data[stand], data[lowest]
return dataimport random
data_list = random.sample(range(50), 10)
Selection_sort(data_list)
>>[4, 12, 20, 27, 28, 25, 30, 39, 40, 43]4. 알고리즘 분석
- 반복문이 두 개 O(𝑛2)
- 실제로 상세하게 계산하면, 𝑛∗(𝑛−1)2
반응형
'Algorithm Study > Algorithm' 카테고리의 다른 글
| 계수 정렬(Counting Sort)알고리즘 (0) | 2020.01.09 |
|---|---|
| 삽입 정렬(insertion sort) 알고리즘 (0) | 2020.01.04 |
| 버블 정렬(bubble sort) 알고리즘 (0) | 2020.01.04 |
| 합병정렬 & 도사정리 (0) | 2019.03.22 |
| 피보나치 수열 합/시간 계산 알고리즘 (0) | 2019.03.10 |





